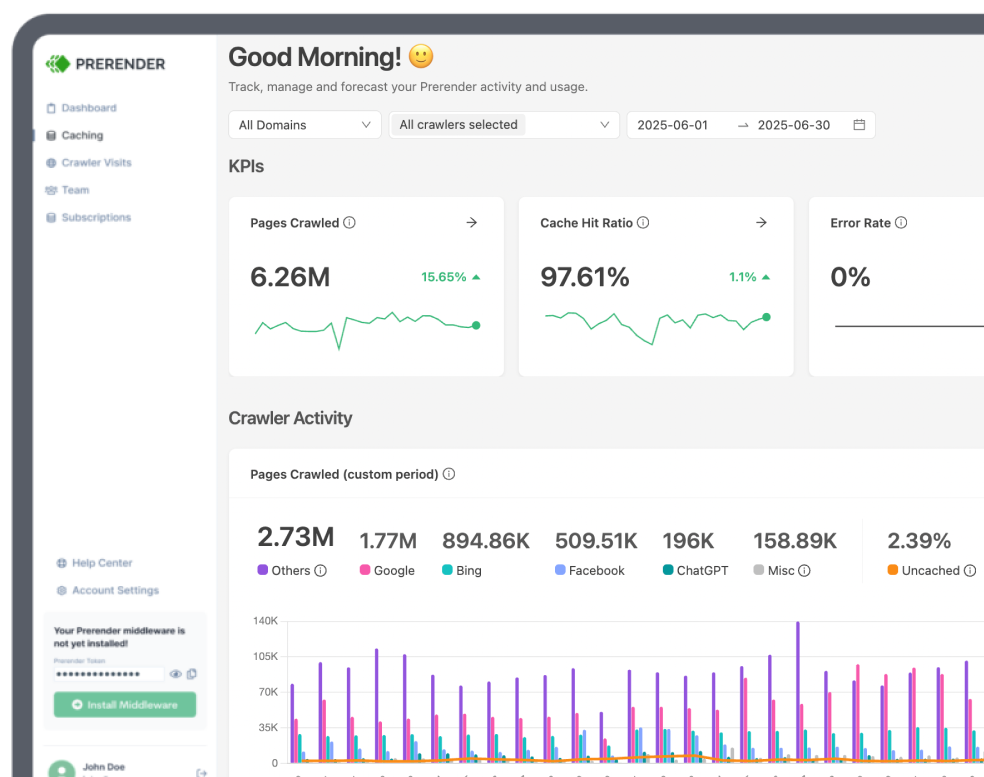
Many SEO managers ignore the role of crawl budget in improving their website’s SEO performance and overall traffic. Yet, crawl budget is the vital elements that get your content crawled and indexed in the first place.
Unfortunately, the crawl budget is limited, and many websites spend it on something that doesn’t bring any SEO benefits to their traffic or online visibility.
In this technical SEO guide, we’ll delve into the seven key factors that significantly impact and potentially decrease your crawl budget. By understanding these factors, you can better prepare to identify and address any issues that can quickly deplete your crawl budget and hinder your website’s visibility.
What is Crawl Budget?
Crawl budget refers to the resources Google spends on crawling and indexing your site. The amount is limited and doesn’t match your website size. Large websites are more prone to depleted crawl budget issues as they typically have more new content waiting to be indexed but a limited or even insufficient crawl budget for Google to execute it all.
There are two factors that increase the crawl budget:
- Crawl rate: mainly related to your server’s speed in responding to Google’s requests
- Crawl limit: influenced by your site’s content quality and freshness as well as website popularity
Further in this blog, we’ll explore the common factors that consume your crawl budget and provide actionable strategies for effective crawl budget management.
How Does Crawl Budget Impact Indexing and SEO Performance?
For your web pages to appear in Google search results, they must first be crawled and indexed by Google’s search engines—and to do this, Google uses your crawl budget.
Now, if your crawl budget is depleted, Google has no more resources to properly crawl and index your content, leaving it partially indexed or not being indexed at all. There are two consequences from this condition: partial and/or no index status.
- Delayed indexation: your new content won’t show up on SERPs as quickly as you want to.
- Missing content: Since your content is only partially crawled/indexed, Google can’t fully understand what your content is about and can’t present it on the SERP as you intended, leading to poor SEO performance.
Factors Impacting Your Crawl Budget and Optimization Tips
1. Faceted Navigation and Infinite Filtering Combinations
The first factor that can influence your crawl budget is poor implementation of faceted navigation and infinite filtering. Faceted navigation (or faceted search) is an in-page navigation system that allows users to filter items.
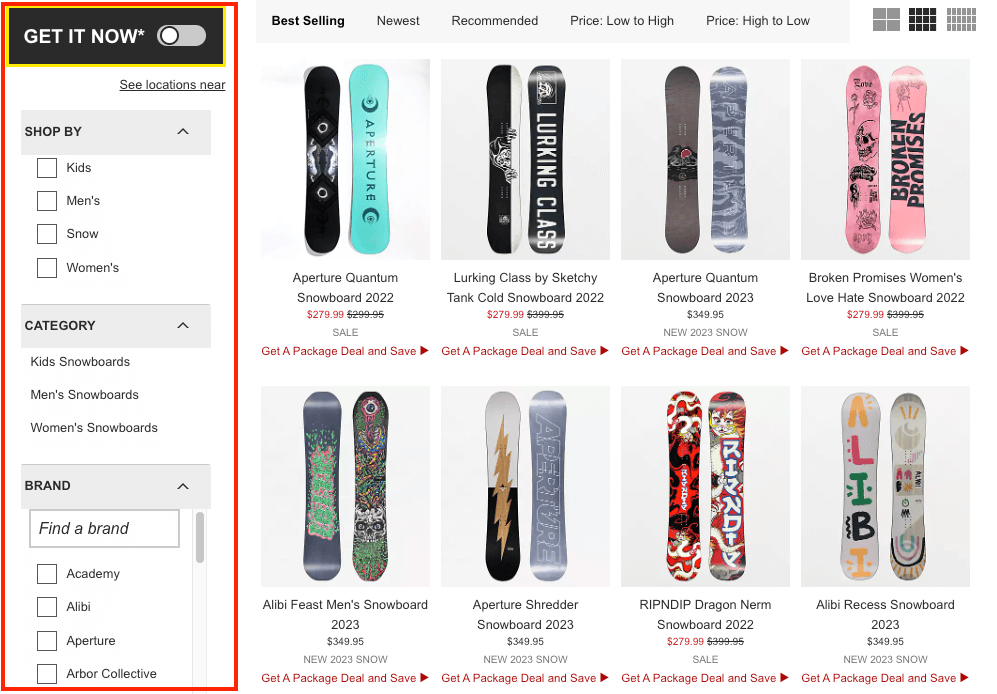
When a user picks one of these options, the page will only display the items that match the parameters selected, making it easier for the consumer to find whatever they’re looking for.
This change is commonly made in two ways:
- Updating the listing dynamically using JavaScript
- Reloading the page to show the new listing without JavaScript
However, what actually interests us is how the URL reacts to this change.
Because of the nature of faceted navigation, in most cases, it generates new URLs based on the facets picked by the user to accommodate for the changes. There are three common facet implementations:
- Applying new parameters at the end of the URL
- Adding a hash to the URL identifying the facets selected
- Generating a new static URL
In the example above, the URL looks as follows:
https://www.zumiez.com/snow/snowboards.html
Let’s see what happens if we apply a few facets to it:
- Shop by > Men’s: https://www.zumiez.com/snow/snowboards.html?en_gender_styles=Men%27s
- Adding Brand > Burton: https://www.zumiez.com/snow/snowboards.html?brand=Burton&en_gender_styles=Men%27s
- Adding Shape > Directional: https://www.zumiez.com/snow/snowboards.html?brand=Burton&en_gender_styles=Men%27s&en_shape=Directional
As you can see, there’s a new URL variation for each facet we chose, which means there’s a new URL to be crawled by search engines.
A crawler works very straightforwardly: it finds a link > follows that link to a page > gathers all links within that page > and follows them too. This process is very fast for small sites, so there’s no need to worry about wasting the crawl budget.
If your site has around 500 pages, Googlebot can crawl it pretty fast. But what happens when faceted URLs enter the mix, and now you have ten variations for every page? Now a 500-page site becomes a 5k-page site, and your crawl budget gets wasted. You don’t want or need Google to crawl ten times the same content. It’s more efficient to help Google crawl your JavaScript pages.
In fact, more likely, only a few important pages will get crawled as every variation will eat the crawl budget, making new and more important pages take longer to be crawled and indexed.
Subfolders, Tags, and Filters
In the case of Magento 2, the ecommerce platform, implementing filters will result in these faceted URLs potentially bloating your site. However, a more distinct problem with Magento is that one URL can be part of several subfolders through categories, generating multiple URL variations that display the same content and waste the crawl budget. Shopify users suffer from something similar, but from tags.
Tags are usually added at the URL’s end, but don’t change much on the page. Like categories, the same product/page can use several tags, creating multiple URL versions that will get crawled without adding any SEO value.
2. Session Identifiers and Tracking IDs
Session IDs and tracking IDs are parameters used for analytics or, in some cases, to remember certain user preferences. When these are implemented through the URL, the server will generate multiple instances of the same page, thus increasing the number of duplicate pages that crawlers need to handle.
Unlike faceted navigation, Google is able to recognize these parameters as irrelevant and choose the original URL, so at least in terms of indexing, it is not very common for irrelevant versions to be indexed nor ranked over the canonical version.
However, it will create duplicate content issues, and Google can even perceive your site as spammy. This will, in turn, impact the crawl budget allocated to your site, as Google doesn’t want to waste resources on low-quality websites and waste the resources assigned on irrelevant instances of every page.
3. Broken Links and Redirect Chains
As said, Google will follow all links and will only bounce out once the crawl budget for the session is exhausted. A crawl budget is about server resources and time; every redirect or broken link is time wasted.
One of the most problematic scenarios is when redirect chains are generated. For every redirect chain, the crawler must jump from link to link until it finally arrives at its destination. If you’ve experienced a redirect before, each jump can take anywhere from a few milliseconds to a couple of seconds – which in machine time is a very long time.
Now, imagine how long it would take for the crawler to get to your content when it has to jump three, four, or seven times. And if you have several chains on your website, you can easily burn your crawl budget just in these chains.
Infinite Redirect Loops
The most dangerous of these chains is the infinite redirect loops.
Basically, each redirect chain should ultimately arrive at a final destination. But for technical mistakes, what happens if the ultimate destination just keeps redirecting to the beginning of the chain?
To visualize this, you can imagine that Page A redirects to Page B > Page B redirects to Page C > and Page C redirects to Page A. This creates a closed loop where the destination page never resolves.
When the crawler goes through this process and realizes it’s stuck within a loop, it’ll break the connection and, most likely, leave your site. Leaving the rest of your pages uncrawled.
4. Unoptimized Sitemaps
Sitemaps are text files that provide URLs and information about them (like hreflang variations) to search engines like Google and Bing. In terms of crawling, sitemaps can help search engines determine which URLs to prioritize crawling and help them better understand the relationship between them.
The key term here is prioritization.
Many webmasters create sitemaps without any strategy in mind, adding all existing URLs to the file and potentially having Google crawl irrelevant page variations, low-quality pages, or non-indexable pages. This issue can also appear when you only rely on your CMS capabilities to generate an automatic sitemap.
Instead, the sitemap should be a vehicle to prioritize the main pages that we want to index and rank. For example, adding conversion-only pages (without ranking intention) to the sitemap is a waste of resources, as having those pages indexed won’t make any difference.
Make sure to only add pages that return a 200 HTTP status code, are relevant for your rankings, and are the canonical URL. Search engines will focus on these pages and use your crawl budget more wisely – it’s also a great way to help orphan pages, or pages deep in the hierarchy, be discovered.
5. Site Architecture
The site architecture of your website is the organization of pages based on taxonomies and internal linking. You can imagine your website’s starting point as the homepage and how, from there, the rest of the website is organized in a hierarchical structure.
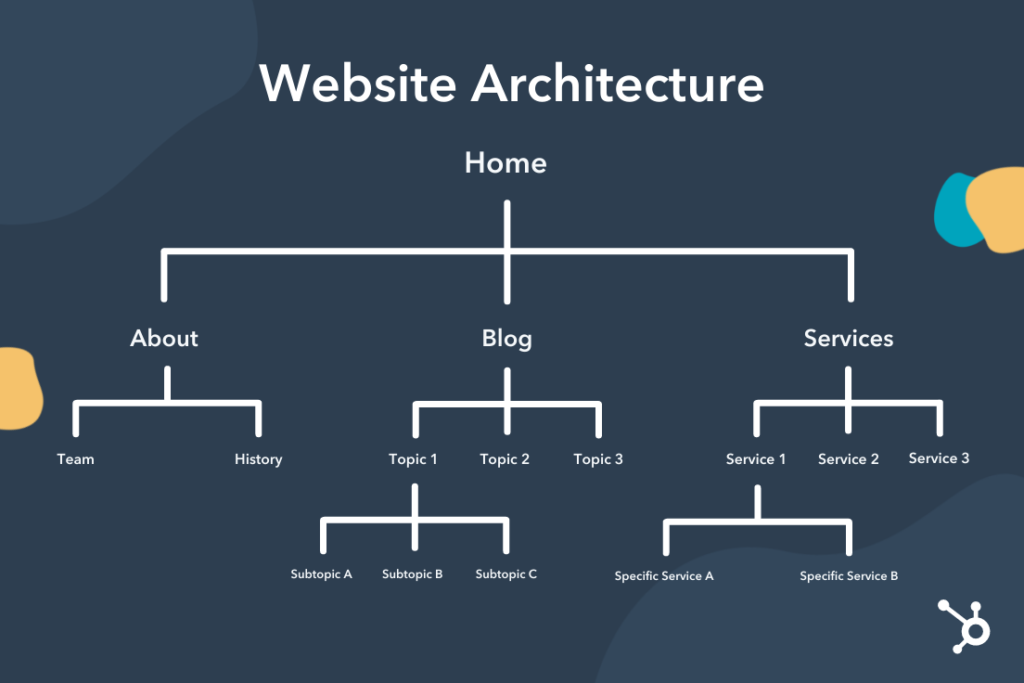
Source: Hubspot
So how does it relate to the crawl budget? In a more raw sense, your site is just a combination of different pages connected by hyperlinks, organized under one domain name. Search engines start crawling from your homepage and then move down through every link they can find.
Through this process, crawlers get to map your website to understand its structure, the relationship between the pages (for example, categorizing them by topics) and get a sense of their importance – more specifically, the closer the page is to the homepage, the more important it is.
This means that pages closer to the homepage are prioritized for crawling, and as the pages get deeper down the structure, it takes more time for crawlers to find them and are deemed less important, so they are crawled less frequently.
It also means that there’s an internal linking dependency. If Page H is only linked from Page G and Page G doesn’t get crawled, Page H won’t be crawled either.
A well-designed site architecture will ensure that all pages are discoverable through the crawling process and help with page prioritization.
6. Page Authority / Backlink Profile
In simple terms, a backlink is a link pointing to a page on your domain from an external domain. These inbound links act like votes for your pages and signal to Google that your content is trustworthy, increasing its authority.
While backlinks are more commonly talked about as a ranking factor, they can also help your website increase its crawl budget.
One of the factors in calculating your crawl budget is crawl demand, which determines how often a URL should be recrawled, and one of the main variables taken into account in this process is popularity – which is calculated by the number of internal links and backlinks pointing to the URL.
If your page is getting a lot of link equity – both internally and externally – it means it’s worth crawling more often, and as more and more of your pages need to get crawled more often, your site’s crawl budget will increase.
Another way backlinks help your site crawl is by discovering your URLs from other websites. If a crawler finds your URL from an outside source, it will follow your link and then all the links from that page, creating a healthy crawling effect the more high-quality backlinks you earn.
Note: Backlinks from authoritative pages, generating a healthy amount of traffic, are more valuable than a massive number of low-quality backlinks from pages without any traffic.
7. Site Speed and Hosting Setup
Site speed is one of the most talked about technical SEO topics because it heavily affects user experience and can definitely make a difference in your SEO performance. It’s such an important metric, Google has broken it down into different aspects in their core web vitals scores.
Understanding that in the crawling process, Google needs to send an HTTP request to the server, download all necessary files and then move to the next link paints a clear picture of why slow response times from your website can be an issue.
Every second the crawler has to wait for the page to respond, it’s a second your crawl budget gets consumed just waiting.
It’s important to notice that it is not just about how your website is built (the code), but also your hosting service can make your website unresponsive – even to timeout.
There are several components to it, but a good place to start is the bandwidth. The hosting plan’s bandwidth determines how much information the server can transfer. Think of this like your internet speed; if you’re a streamer with a slow internet connection, no matter how fast your audience’s internet speed is, it will be a slow, painful transmission.
But it’s not just about consuming your crawl budget. Google will avoid overwhelming your server at all costs. After all, the crawling process is traffic coming to your site. If your website timeout or takes way too long to load, Google will lower your crawl budget thinking your server can’t manage the current frequency.
How Prerender.io Improves Your Crawl Budget
If you’re building a single-page application (SPA), you’re already dealing with two or more of these issues. On top of that, JavaScript makes the whole process even harder for search engines, and it most definitely slows down your site.
It’s very common for SPAs to:
- Add links dynamically via JavaScript, making it so that Google will need to render the page before it can find the next URLs to crawl
- Generate hash and faceted URLs, creating, in some cases, a massive number of URLs for Google to crawl
- Score low on core web vitals, especially because of JavaScript execution time
To help you optimize your crawl budget without recurring to time-consuming workarounds, Prerender fetches your URLs, caches all necessary resources, creates a snapshot of all fully rendered pages, and then serves the static HTML to search engines. Crawlers won’t need to deal with any complexities or wait for your pages to load. Prerender will provide it with the HTML page so it can move to the next one without generating bottlenecks.
Learn more about how Prerender.io works in this video, or read more about the benefits here.
Optimize Your Crawl Budget for Healthier SEO
Your website’s crawl budget can fluctuate based on factors like content quality, popularity, and performance. While it’s beneficial to strive for a larger crawl budget, it’s equally important to address potential issues that can drain it.
By examining the seven factors that influence your crawl limit, you can identify areas to focus on during your next SEO audit and implement solutions, such as using Prerender.io.
Want to see how easy it is to optimize your crawl budget with Prerender.io? Join 100k+ brands like Salesforce, Figma, and Hubspot and start your free 30-day trial today.
FAQs – Factors Influencing Crawl Budget
Answering some common questions about crawl budget, factors that impact it, and some crawl budget optimization tips.
1. How Can I Increase My Crawl Budget?
There are two ways to increase your crawl budget:
1. Improve your server’s responsiveness, maintain high-quality content, and refresh your content regularly.
2. Ensure that you don’t spend your crawl budget on SEO activities that don’t impact your bottom line. For example, poor site architecture and interlinking exhaust Google when crawling your site, and you don’t block pages with robots.txt on pages that don’t need to be indexed (e.g., login and cart pages).
2. How Does Infinite Redirect Loops Deplete My Crawl Budget?
Infinite redirect loops mean Google is continuously crawling your pages. It goes from Page A > B > C > and back to A. Every crawl costs you a crawl budget, and infinite redirect loops trap Google in doing infinite crawling.
3. Why Is a JavaScript Website Prone to a Depleted Crawl Budget?
JavaScript websites are prone to a depleted crawl budget because Google requires more crawl budget when indexing JS-based content than HTML-based content. To index HTML pages, Google only needs to crawl and index them. To index JS pages, Google needs to crawl, render, and index them. You can learn more about Google’s JavaScript indexing process here.