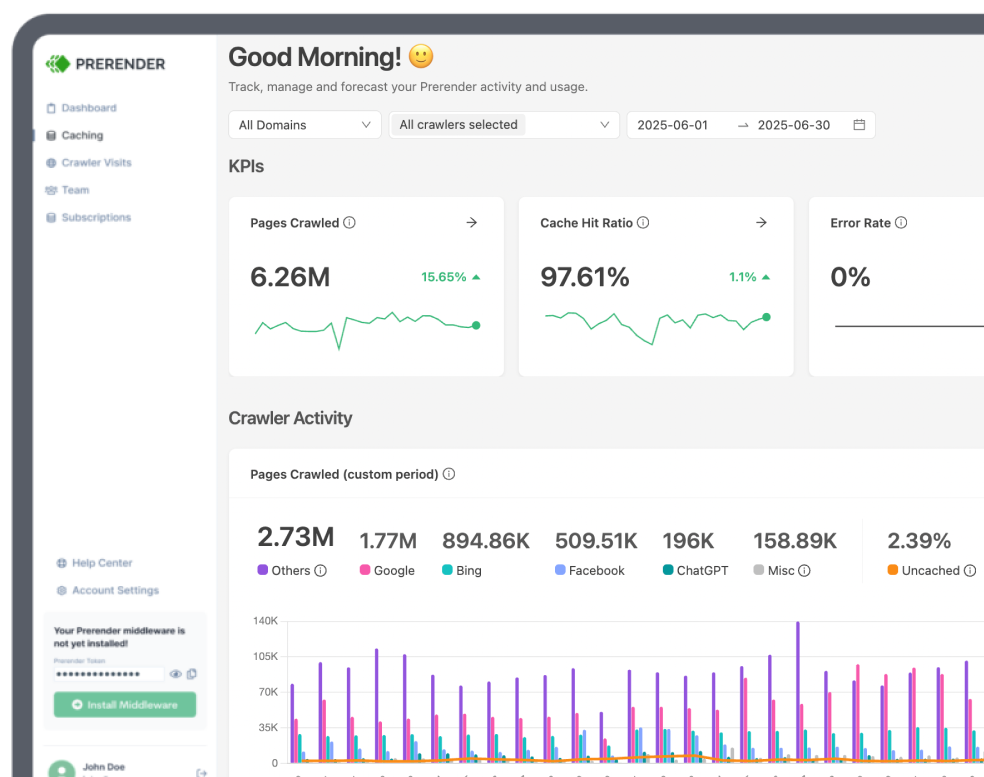
Crawl Budget is a frequently misunderstood term in SEO and digital marketing. This largely stems from a lack of understanding about how search engines work.
There are currently about a trillion pages on the World Wide Web. Organizing those pages and assessing their relative value is one of the most challenging tasks search engines face.
It’s a problem for website owners when Googlebot doesn’t crawl every page on their website. When this happens, it’s usually because of one of two reasons:
1. Google has limited resources and thus has developed mechanisms to filter low-quality pages and spam.
2. Google often limits the number of pages it will crawl so that your server does not crash.
So if Google spends its resources trying to crawl every page on your website, including the low-quality ones, your more valuable pages may not get crawled. This is why optimizing your crawl budget is necessary.
In this article, we will cover the fundamentals of crawl budget optimization and address common issues website owners have when making their pages more crawlable.
What Is a Crawl Budget?
A crawl budget is the predetermined number of requests that a crawler will execute on a website within a certain period.
That number is how many and which pages Googlebot will crawl on your website.
The crawl budget is determined entirely by the search engine. Once that budget is exhausted, the web crawler automatically stops accessing your site’s contents and moves on to the next website.
The reason for assigning crawl budgets to websites is that search engines like Google can only crawl so many web pages. To accurately tend to the millions of websites on the Internet, Google divides its resources among them as equally as it can. Every website’s crawl budget is different and depends on several factors:
- Website size: Larger websites are generally allocated with bigger crawl budgets.
- Server setup and site performance: Server load times and site performance are also accounted for during crawl budget allocation.
- Links on your site: Internal linking structures play a vital role, and dead links or redirect chains can deplete your crawl budget.
- Frequency of content updates on your site: Google allocates more time for crawling to sites with regular content updates.
Why Crawl Budget is Important for SEO
Crawl budget management isn’t as crucial for relatively small websites with only a few pages, but becomes a concern for moderately-sized or larger ones.
SEO involves making many small but collectively significant changes that affect your website’s growth over time, rather than making big changes to get fast results. Your job as an SEO professional or web administrator is to optimize thousands of little things as much as you can.
Search engines have finite resources and cannot crawl and index each web page they find on a massive and constantly changing Internet. This is why crawl budget becomes so important, especially for larger websites with many pages.
While crawlability is less important for webmasters with smaller sites, even a website that seems small at first glance can contain thousands of URLs. Faceted navigation,which is common in many online stores and eCommerce websites, can easily convert 100 pages into 10,000 unique URLs, which can become a problem when being crawled and indexed. Additionally, the presence of bugs in the CMS can produce unwanted results.
It is generally recommended for SEO best practices that all webmasters evaluate their website’s crawl budget, regardless of its size or structure.
How Does the Crawl Budget Process Work?
Understanding what a crawl budget is and why it’s important is one thing, but website owners and SEO teams must also understand how Google crawls websites.
How Search Engines Work
Search engines like Google use three basic processes to catalogue web pages: crawl, index, and rank.
Crawling: Finding Information
Search engine crawlers begin by visiting websites from their list of web addresses obtained from past crawls and sitemaps, provided by various webmasters via tools like Google Search Console. Crawlers then use links on the sites to discover other pages.
Indexing: Organizing Information
Next, the crawlers organize the visited pages by indexing them. The web is essentially a giant library that grows every minute without any central filing system. Search engines render the content on the page and look for key signals that tell them what the webpage is about (e.g. keywords). They use that information to index the page.
Ranking: Serving Information
Once a web page is crawled and indexed, search engines serve the results of user queries according to the ranking algorithm with the indexed pages.
The Specifics of Crawling
Gary Illyes, a Webmaster Trends Analyst at Google, gave us a clearer picture of Googlebot’s crawling process in a 2017 blog post. According to him, the crawl budget is primarily based on two components: crawl rate limit and crawl demand
Crawl Rate Limit
A crawl rate limit refers to how frequently your website is crawled.
Crawling uses up server resources and bandwidth limits allocated to the site by its host. This is why search engines like Google have systems in place to determine how frequently it visits websites, so that the site can be crawled sustainably.
This means there is a limit to how many times a particular website will be crawled. The crawl rate limit prevents crawlers from disrupting your website performance by overloading it with HTTP requests. This enables search engines to determine how often they can visit your website without causing performance issues.
This process has drawbacks as well. Manually setting the crawl rate limit can cause a website to suffer issues like:
-
- Low-Crawl Rate: when new content on your website remains un-indexed for long periods
- High-Crawl Rate: when the monthly crawl budget is exhausted unnecessarily through repeated crawling of content that doesn’t need to be crawled.
This is why it is generally recommended for web admins to leave crawl rate optimization to the search engines.
Crawl Demand
Crawl demand determines the number of pages on a website that a crawler will visit during a single crawl. It’s primarily impacted by the following factors:
-
- URL Popularity: The more traffic a page gets, the more likely it is to be indexed.
- Staleness: Pages with regular content updates are considered new URLs and are more likely to be indexed than those with rarely updated content or “stale URLs”.

What Are Factors That Affect Crawl Budget?
A lot of factors determine your crawl budget, and many of them cause recurring issues for website owners.
Faceted Navigation
Ecommerce websites often have dozens of variations of the same product, and need to provide a way to filter and sort them for users. They do this by way of faceted navigation – creating systematized, unique URLs for each product type.
While faceted navigation is very useful for users, it can create a host of problems for search engines. The filters applied often create dynamic URLs, which appear to web crawlers as individual URLs that each need to be crawled and indexed. This can exhaust your crawl budget unnecessarily and create duplicate content on your website.
Related reading: Ecommerce Requests That Waste Your Crawl Budget.
Session Identifiers and Duplicate Content
URL parameters like session IDs or tracking IDs all end up creating several unique instances of the same URL. This can also create duplicate content issues that hurt your website’s rankings and exhaust your crawl budget.
Soft 404 Pages
A soft 404 occurs when a broken web page responds with a 200 OK HTTP status code rather than a 404 Not Found response code. This causes the crawler to attempt a crawl on that broken page and consume your crawl budget.

Poor Server and Hosting Setup
Poor server and hosting setup results can cause your website to crash frequently. The crawl rate limit restricts crawlers from accessing websites that are prone to crashing. Thus, they will often avoid websites hosted on poor server setups.
Render-Blocking CSS and JavaScript
Every resource that a web crawler fetches while rendering your webpage is accounted for in your crawl budget, including not only HTML content but CSS and JS files too.
Webmasters need to ensure that all these resources are being cached by the search engine and minimize the performance issues, and that external style sheets don’t cause problems such as code-splitting.
Broken Links and Redirects
A broken link is an Ahref hyperlink that redirects the user or bot to a page that does not exist. Broken links can be caused by a wrong URL in the link or a page that has been removed. When 301 redirects link to each other in a sequence, it can frustrate human users and confuse search engine bots.
Every time a bot encounters a redirected URL, it has to send an additional request to reach the end destination URL. This issue becomes more serious the bigger a website is. A website that has at least 500 redirects gives a crawler a minimum of 1,000 pages to crawl. A redirected link can send a crawler through the redirected chain, exhausting your crawl budget on useless redirect jumps.
Site Speed and the Hreflang Tag
Your website needs to load quickly enough for the web crawler to access your pages efficiently. These crawlers often move on to a different website altogether when they encounter a page that loads too slowly; for example, if it has a server response time of more than two seconds.
Alternate URLs defined with the hreflang tag can also use up your crawl budget.
XML Sitemap
Search engines like Google always prioritize the crawling schedule for URLs that are included in your sitemap over the ones that Googlebot discovers while crawling the site. This means that creating and then submitting your website’s XML sitemap to Google Webmasters is vital to its SEO health. However, adding every page to the sitemap can also be harmful, as the crawler having to prioritize all your content uses up the crawl budget.

How to Calculate Your Crawl Budget
Tracking and calculating your crawl budget is tricky, but it can give you some very valuable insights about your website.
First, you need to know how many pages you have. You can get that number from your XML sitemap, by running a site query with Google using site:yourdomain.com or by crawling your website with a tool like Screaming Frog. Once you know how many web pages you have, open Google Search Console for your website and find the Crawl Stats report under the Settings section.
This shows Googlebot’s activity on your site within the last 90 days. Here, you can find the average number of pages crawled per day. Assuming that number stays consistent, you can calculate your crawl budget with the following formula:
average pages crawled per day × 30 days = crawl budget
This information is very useful when your crawl budget needs to be optimized. Divide the number of pages on your website by the average number of pages crawled per day.
If the result is a number higher than 10, it means that you have 10 times more pages on your site than what Google crawls per day, meaning you need to optimize your crawl budget. If the number is less than 3, your crawl budget is already optimal.

How to Optimize Your Crawl Budget
Optimizing the crawl budget for your website simply means taking the proper steps to increase it. By improving some key factors that affect it, like faceted navigation, outdated content, 404 errors, and 301-redirect chains, you can be well on your way to increasing your website’s crawl budget. Here’s how:
1. Optimize the Faceted Navigation
Faceted navigation can eat up your crawl budget if not implemented correctly, but that shouldn’t restrict you from using it. You just need to do some tweaking to optimize it.
-
- You can add a ‘noindex’ tag that informs bots about the pages not being indexed. This will remove the pages from the index but still waste your crawl budget on them.
- Adding a ‘nofollow’ tag to any faceted navigation link will restrict the crawler from indexing it, freeing up your crawl budget by immediately removing those URLs.
2. Remove Outdated Content
Removing outdated content will free up a lot of your crawl budget. You don’t need to physically delete the pages containing that content, you just need to block crawlers from accessing it as you did with faceted navigation links.
This would reduce the number of crawlable URLs in your index and increase your crawl budget.
3. Reduce 404 Error Codes
To reduce the number of 404 error codes on your website, you need to clean up your broken links and send a 404 Not Found response code to the web crawler. This helps crawlers to avoid accessing those links and again, increase your crawl budget by reducing the number of crawlable URLs for your site.
4. Resolve 301-Redirect Chains
Broken links and 301-redirect chains can also needlessly exhaust your crawl budget, and cleaning them up should be a part of your regular website maintenance. To avoid this problem and increase your crawl budget, you need to improve your internal linking and resolve any outstanding redirect chains:
- Perform a full crawl of your website using a tool like Screaming Frog.
- Once the crawl is done, identify the redirected URLs as well as the source page where the particular link is placed.
- Finally, update these links so that all the links point directly to the destination URLs.
You should also avoid orphan pages, which are present in the sitemap but aren’t internally linked, effectively stranding them within your website’s architecture.
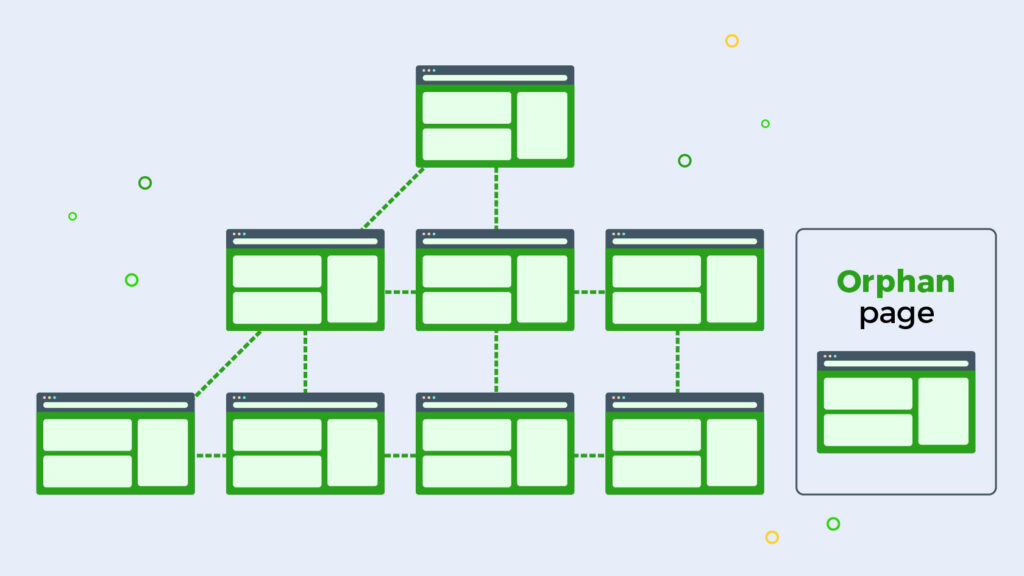
5. Clean and Update Your Sitemap
Check your sitemap in regular intervals for included non-indexable URLs as well as indexable URLs that are mistakenly excluded from it.
By refreshing your sitemap, you ensure that search engine crawlers are informed about any modifications to your website, encompassing the addition or updating of pages.
6. Improve Site Speed and Hreflang Tag
Improving your website’s speed not only provides a better navigation experience but it also increases the site’s crawl rate. Sites with a slow loading speed are often avoided by Googlebot altogether. Optimizing page speed involves many technical SEO factors, but executing them helps your crawl budget
Using the <link rel=”alternate” hreflang=”lang_code” href=”url_of_page” /> in your page’s header helps to point out the localized versions of the pages to the crawler and avoids exhausting your crawl budget.
7. Avoid the Use of Parameters in your URLs
You want to avoid adding parameters to your URLs because it makes it harder for search engine crawlers to index your website. This is because it gives more details about your page content. Using static URLs is a much better choice. For example, using example.com/page/123 instead of a dynamic one like example.com/page.id=123 is a better practice. The result will be that your website will become easier to access by search engine crawlers.
8. Delete Duplicate Pages
Duplicate pages have a confusing effect on search engine crawlers, negatively affecting your traffic, and wasting your crawl budget. To properly optimize your crawl budget and prevent the search engine bots from scanning the same content more than necessary, you need to ensure that there are no duplicate pages on your site.
9. Use HTML Wherever Possible
Even though Googlebot has become more efficient in crawling JavaScript files along with indexing Flash and XML, that is not the case for other popular search engines like Bing or DuckDuckGo. This is why using HTML wherever you can is always recommended, as all search engine bots can crawl HTML files easily.
10. Use Robots.txt for Crawling the Important Pages
Utilizing your website’s robots.txt file is a very efficient way to optimize your crawl budget. You can manage your robots.txt to allow or block any page of your domain. Doing this with a website auditing tool is recommended for larger websites where frequent calibrations are required.
11. Prioritize Your Content Structure and Internal Linking
The importance of a well-developed content architecture cannot be overstated. It ensures the efficient and effective dissemination of information, tailored to your target audience’s needs. As users increasingly seek out easily digestible and meaningful content, focusing on your information’s structure becomes more critical.
Complementing this is the vital practice of internal linking. The benefits of effective internal linking extend to both users and search engines, as it enhances your site’s navigability and discoverability, leading to a more user-friendly experience. Pages that lack internal links may become hard to locate and may not be crawled by search engines as frequently. Additionally, a strategic internal linking strategy can enhance your search engine rankings for keywords associated with linked pages.
Use Prerender to Optimize Your Crawl Budget
Crawl budget optimization is an inexact science that involves a lot of moving parts and ongoing website maintenance tasks that can be very cumbersome.
Using Prerender allows Google to easily crawl and index your website, whether it’s made using HTML or JavaScript, and no matter how many web pages it has. When you optimize your budget for crawling Google, you free up mental bandwidth for more important tasks that focus on higher-level SEO strategy.
Try Prerender today with a free 30-day trial.
FAQs
How Often Does Google Recalculate a Website’s Crawl Budget?
Google doesn’t publicly disclose exact timelines for recalculating crawl budgets. However, it’s an ongoing process that can change based on various factors like site performance, content updates, and overall site health. It’s best to consistently maintain good SEO practices rather than expecting immediate changes to your crawl budget.
Can Improving my Core Web Vitals Affect Crawl Budget?
Yes, improving your site’s Core Web Vitals can positively impact your crawl budget. Better page speed and user experience metrics signal to Google that your site is high-quality and efficient to crawl. This can lead to more frequent and thorough crawling, effectively increasing your crawl budget over time.
Can I Directly Request an Increase in Crawl Budget From Google?
There’s no direct way to request an increase in crawl budget from Google. However, you can indirectly influence it by improving your site’s overall quality, speed, and structure. Implementing the optimization techniques mentioned in the article can help increase your crawl budget over time.
How Does International SEO Affect Crawl Budget?
International SEO can significantly impact crawl budget, especially for large sites. Each language or regional version of a page is considered a separate URL, which can quickly multiply the number of pages Google needs to crawl. To optimize crawl budget for international sites:
- Use hreflang tags correctly to indicate language and regional variants
- Ensure your site structure clearly separates different language/regional versions
- Use a proper international URL structure (ccTLDs, subdomains, or subdirectories)
- Avoid duplicate content across different language versions by properly localizing content
What are Tools to Help Optimize my Crawl Budget?
Several tools can help analyze your website and identify crawl budget issues. Some popular options include:
- Screaming Frog: Crawls your website and identifies broken links, redirects, and other technical SEO issues.
- Google Search Console: Provides valuable insights into crawl stats, indexing status, and mobile usability.
- Prerender: Helps search engines efficiently crawl and index JavaScript-heavy websites in a fraction of the time.