In 2024, around 98.7% of all websites use JavaScript in one way or another. And it’s easy to understand why. JavaScript allows developers to add functionality to otherwise static websites. Things like filtering content options or generating dynamic graphs based on data.
That’s great for users but not for search engines, as it makes it harder for them to read the information on your sites, to the point it can be harmful to your organic traffic performance.
If you’re serious about growing your business through organic search and improving your user experience, it’s crucial to understand how Google handles JavaScript. For example, its limitations and what you can do to facilitate indexing your dynamic pages without losing precious content.
Seeing JavaScript-Based Sites Through Google’s Eyes
Although it fluctuates, Google has maintained its dominance over all competing search engines for years, hitting a 91.88% global market share in June 2022.
For that reason, let’s focus on how Googlebot finds, crawls, and indexes your content and what exactly happens when it finds dynamic content on your website.
How Google Crawls and Index Websites
Nowadays, many people associate the internet with search engines, as if the internet were the search engines we use to find information and websites.
However, the reality is that the internet is composed of billions of websites that link to each other, and search engines are kind of like a directory where you can find those websites in a categorized format, allowing you to find them with keywords or queries.
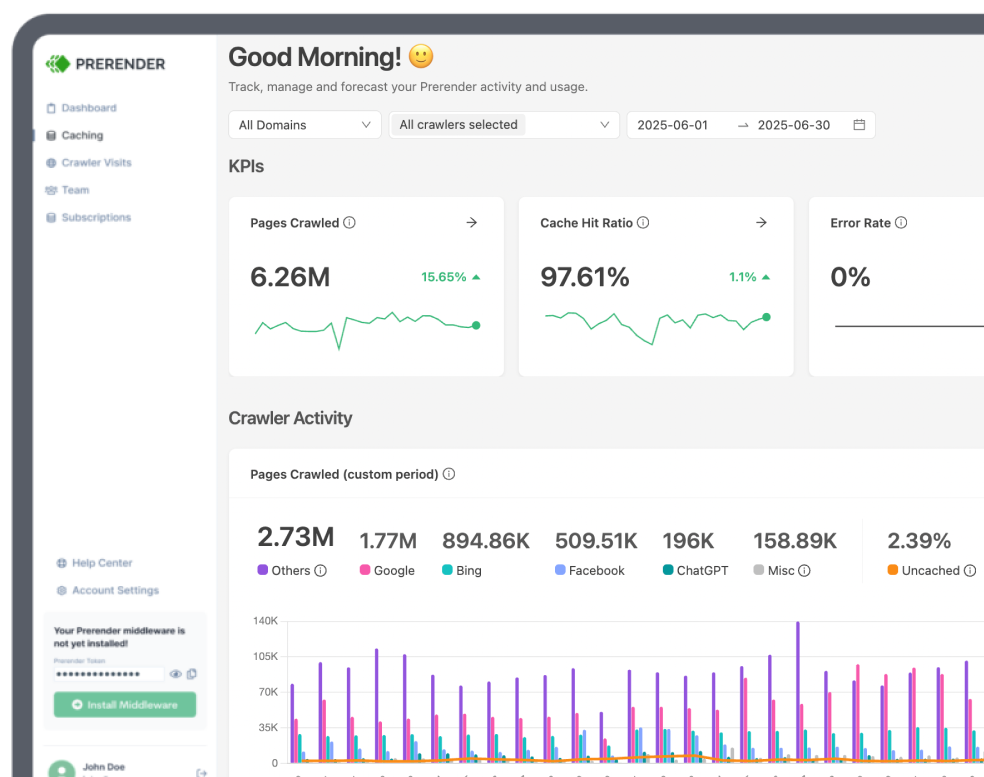
For this to work, Google needs to find those pages first. This “discovery” process is called crawling. In this process, a bot (crawler) follows a link to a new page and then follows the links on that page to the next.
Through crawling pages, Google can find new pages and understand their relationship through the crawling process. Also, at this stage, Google will render the page using all the files fetched during crawling: the HTML, CSS, JavaScript, and any other file it needs to build the page.
Returning to the directory structure, the process through which Google categorizes the pages and adds them to its list is called indexing. This stage includes “processing and analyzing the textual content and key content tags and attributes, such as <title> elements and alt attributes, images, videos, and more.”
In other words, indexing will analyze all the data associated with your page (language, location, structure, content, structured data, etc.) and add it to their database.
Note that a key component of successful indexing is rendering. If Google can’t see what’s on your page, it won’t be able to index it.
Related: 6-Step Recovery Process After Getting De-Indexed by Google
How Google’s Renderer Works
Let’s go deeper into this whole process. When Google finds a URL, it doesn’t crawl it immediately. It first reads the robot.txt file to make sure you’re not blocking this page from being crawled. If it’s allowed, then it will queue the URL for crawling.
Once the page is crawled, all new URLs found will be sent to the crawling queue, while those already crawled will move to the rendering queue to pass through the renderer, and here’s where the magic happens.
Note: If your robot.txt file blocks a page from being indexed, Google won’t render the page.
In simple terms, rendering is the process of constructing a page using all fetched files and transforming (hyper)text into pixels – just like browsers do.
Google’s Process by Google Search Central
Google uses an instance of Google Chrome with Puppeteer to render the page and see the website just like users do.
Once the page is rendered, Google will take a snapshot of the result, compare it to the raw HTML version and finally return the page for indexing. Otherwise, Google can’t understand the page’s quality, content, and elements and won’t be able to index the page at all.
Why You Shouldn’t Rely On Google’s Renderer: Crawl Budget and Indexing Issues
It seems like Google has everything figured out, so what’s the problem, then?
It all comes down to resources. Crawling and rendering one page is easy enough, but performing this process with billions of pages per day becomes challenging. To add even more stress to Google’s system, they can’t just crawl once and call it. If pages get updated or changed, Google needs to re-crawl old pages to ensure their index is up to date and always shows users the best results.
Now, because search engines’ resources are finite, they allocate a crawl budget – a “predetermined number of requests that a crawler will execute on a website within a certain period” – for every website. After the window is gone, Googlebot will stop crawling your site, no matter if there are still pages missing from the index.
Within this crawl budget, it compresses the amount of waiting time on the crawling queue and rendering queue and the time it takes for the renderer to fetch the additional content necessary to render your dynamic pages. As a result, optimizing the crawl budget is crucial for larger sites.
In addition, there are a lot of things that can go wrong. For example, Google is unable to render the entire page content, putting you at a disadvantage in search results, or consuming your crawl budget too quickly, preventing other pages from being discovered.
How Prerender Solves the JavaScript vs. SEO Problem
When rendering dynamic pages, developers have three solutions available.
The most common solution is using server-side rendering (SSR). Instead of making Google render your pages, this process takes place directly on your servers. In other words, when a user agent (like Googlebot) sends a request to your URL, your server will render the page and return a fully rendered version of the DOM, thus saving a lot of time and resources to users and search engines.
The main problem with this approach is its cost, as you’re now the one having to pay for all the processing power required for the rendering process. Not to mention it’s also a complicated process to set up and will need a lot of hours from the development team to configure.
Note: Something to keep in mind is that to implement SSR within your server, your backend will need to be written in Node.JS, as the solution is not compatible with backend languages like JavaScript or Go. If that’s your case, we’ll share the best solution later in this article.
On the other hand, JavaScript frameworks (like Vue and React) default to client-side rendering, passing the burden of rendering dynamic content to the browser. Although it’s more cost-effective, most search engines can’t execute JavaScript, so all they’ll get is a blank page.
But there’s a third option: prerendering.
Even Google recommends prerendering for the short term!
What is Prerendering?
As its name implies, prerendering consists of caching a fully rendered version of your pages and serving them to search bots when they send a request to a prerendered URL.
For this to work, your servers need to distinguish between human users and bots, cache the fully rendered version of your pages, and, of course, be able to perform the rendering process.
However, this would quickly scale into undesired costs and maintenance. Instead, you can use a solution like ours, Prerender, to optimize your JavaScript website for search engines for a fraction of the price it would be to implement and handle the entire process yourself.
Looking to get started with Prerender? Start here.
How Prerender Works
To use Prerender, all you need to do is install the appropriate middleware (based on your tech stack) to your backend/CDN/web server and test it to make sure it’s working correctly. No complicated workarounds or maintenance. Watch the video below for a quick explainer.
Note: Unlike a hardcode solution, you can integrate Prerender into your site no matter your tech stack. We covered languages like C#, Python, Ruby, Java, and more.
When your server identifies a user agent as a bot requesting your page, it will send a request to Prerender. If it’s the first time, the page won’t be in the cache (cache miss), so Prerender will fetch all necessary files from your server, render the page and, after a few seconds, send the page as a rendered static page.
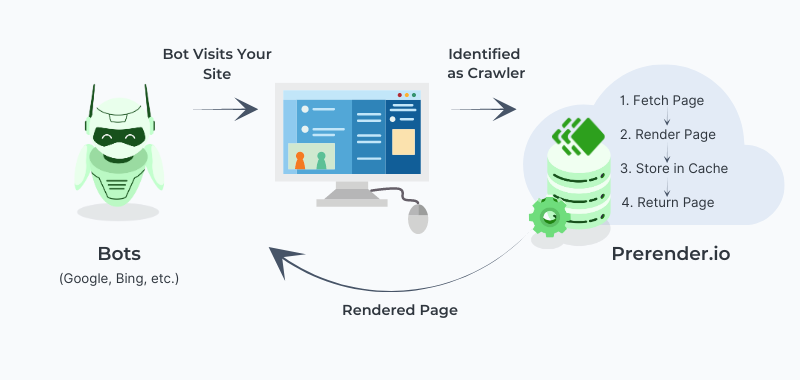
Just like Google, Prerender has its own Puppeteer instance (using the latest Chrome technologies) to ensure that the page is fully rendered, no matter which technologies you use.
Once the page is in the cache, Prerender will serve this cache version (cache hit) to all bots in the future, boosting response speed, crawl budget, and, most importantly, providing an accurate snapshot of the page for indexation.
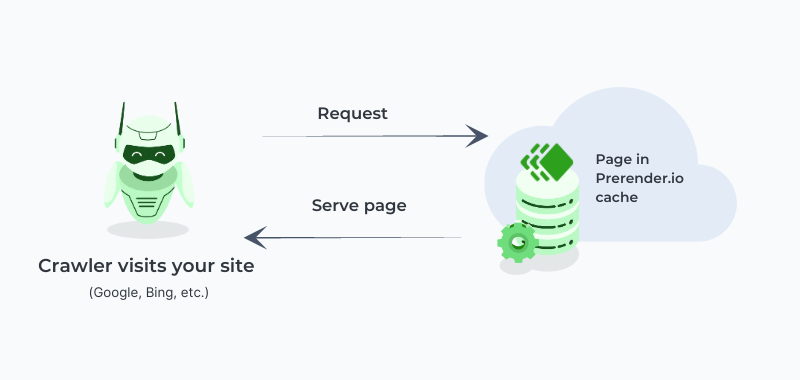
Note: The crawler never knows that you are using Prerender.io since the response always goes through your server.
The middleware will send the traffic to the normal server routes for human users, so the user experience doesn’t see any compromise or alteration.
How Prerender Manage Changes on Your Pages
Your pages continuously change and evolve, whether it’s a change in data or periodic updates, your content won’t stay still, but your cache version will.
With server-side rendering, the rendering process is performed with every request to the server, but Prerender stores the rendered version and uses it to feed search bots.
That’s good because it heavily reduces processing costs and time. But what happens with changes, then?
Prerender comes with a feature called recaching. It allows you to set a timer for Prerender to fetch the pages again, create a new snapshot from the updated content and store it in the cache to be served in the subsequent request.
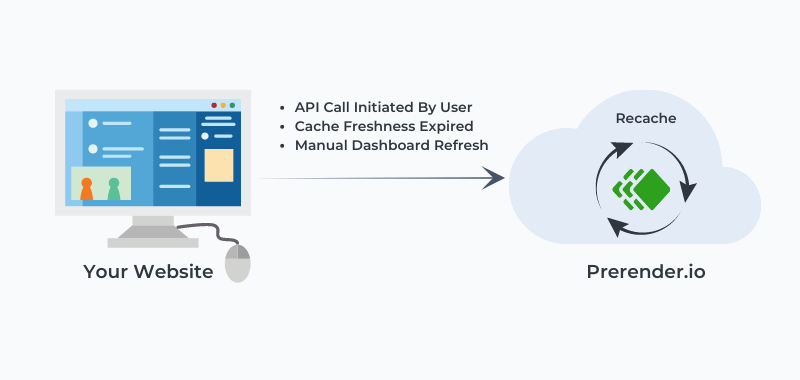
This functionality is crucial to allow Google to always find the most up-to-date version of your pages, so it doesn’t miss new links on the page, on-page optimizations, or hurt the dynamic aspect of the page.
Have more questions? This video below covers some commonly asked questions from businesses like yours.