Fixing duplicate content is a relatively quick win, depending on the cause, that can boost your organic traffic. Most of these issues come from unintentional technical errors that can cost you a lot of money if they go unaddressed.
In this article, we’ll walk you through a quick audit approach for finding URLs affected by duplicate content issues, fixing them, and proposing a content approach to keep your site free of duplicate pages in the future.
What is Duplicate Content?
According to Google, “duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content in the same language or are appreciably similar. Mostly, this is not deceptive in origin.”
It’s important to frame this concept according to Google’s parameters because, by definition, we can unintentionally end up with issues even though we’re not actively copying content from other sources. And, it could happen even if pages are too similar to one another, like when multiple URLs point to different variations of the same product in eCommerce sites.

What’s the Problem with Duplicate Content in SEO?
However, most importantly, we care about duplicate content because it has real consequences for our SEO performance. Specifically, it generates all sorts of indexing and backlink dilution.
When Google considers two or more pages to be duplicates, it will choose which one is the original version and ignore the rest of them, which means fewer pages indexed and fewer ranking opportunities.
Also, Google may very well pick an undesirable URL full of parameters and filters for its index, making you compete with an under-optimized version of the page.
Further, duplicate content, especially if your website generates a lot of it, can harm your backlink profile. Because “the same” content is housed on different URLs, multiple users leveraging your content pieces as a resource may link to multiple different pages to refer to the same information, so instead of having all backlinks pointing to one page and gaining authority, you can end up splitting backlinks across multiple pages, thus diluting your link juice.
Warning: of course, avoid copying content from other websites or trying to manipulate the algorithm by creating a variation of the same page. If you do, Google may penalize your website.
How to Find Duplicate Content [Tools and Approach]
Before we fix our sites, we need to find the issues. Although there are many methods you can employ, here’s a simple approach you can use:
1. Check the Coverage Tab in Google Search Console
In Search Console, go to the “coverage” tab, and tick the excluded checkbox.
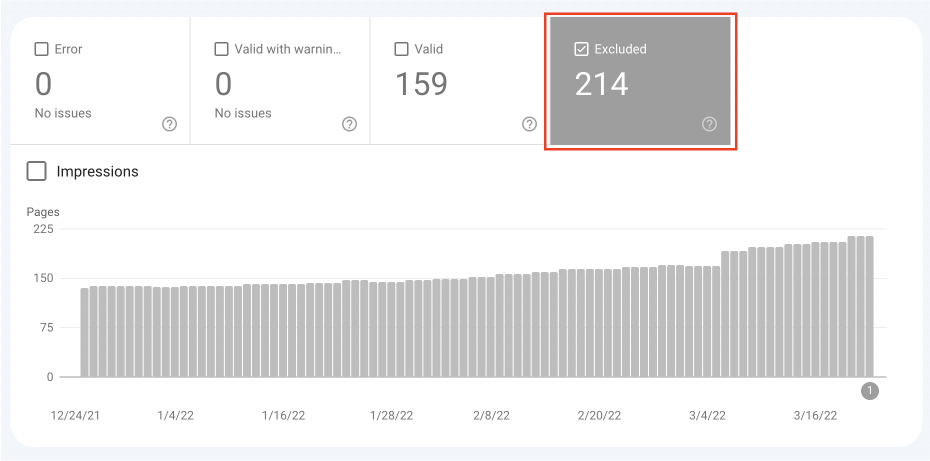
It will show you several reports with all the affected pages organized into categories. If you have too many types of issues, you can filter this list by type containing “duplicate.”
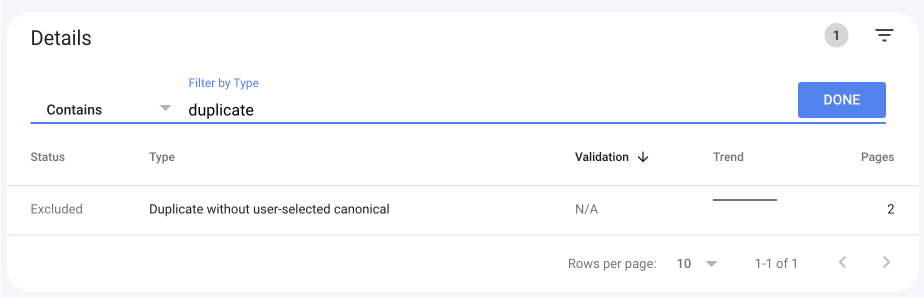
Although there’s only one type in our case, the main categories you’ll see for duplicate content are:
- Duplicate without user-selected canonical
- Duplicate, Google chose different canonical than user
- Duplicate, submitted URL not selected as canonical
Check these reports to make sure there are no URLs excluded without intention.
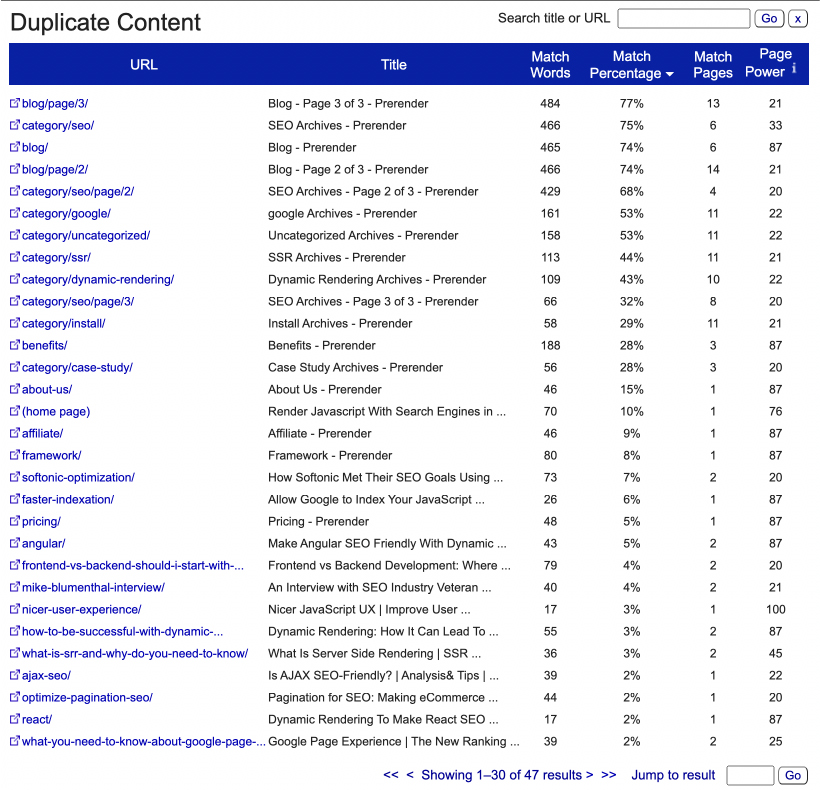
2. Check for Exact Duplicates and Near Duplicates with Screaming Frog
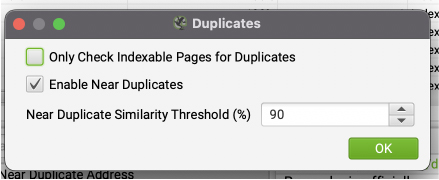
By default, Screaming Frog will look for exact duplicates, but you’ll need to request near-duplicate checks manually. In Screaming Frog, go to configuration > content > duplicates and tick the checkbox as shown in the image below.
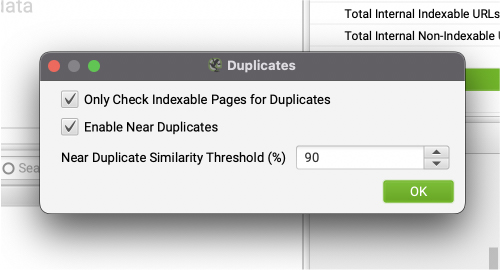
You can also change the similarity threshold if you want it to spot content with a lower percentage of similarity. Still, 90% would be the best option in most cases.
After running the crawl, click on the Content tab and select Exact Duplicate from the dropdown menu. You’ll see a full report with all the pages that are exactly the same from HTML to text.
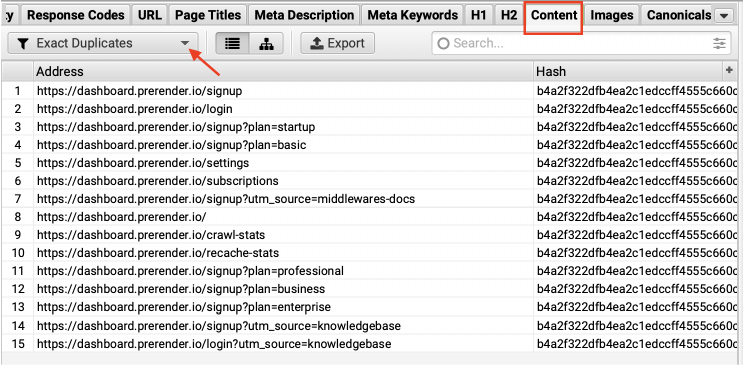
For more details, click on the URL you want to check and go to the Duplicate Details tab in the window beneath to see all the URLs that are an exact duplicate of the one selected.
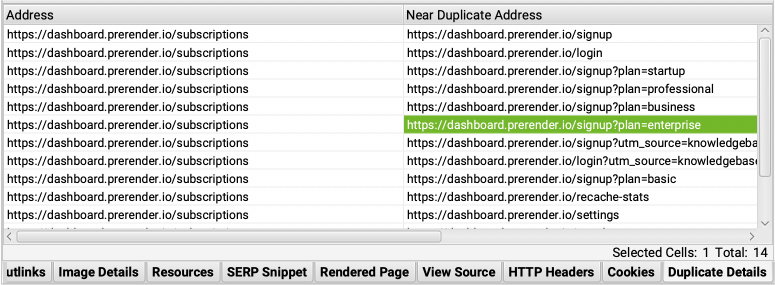
However, if we go to the Near Duplicate report, it has nothing. That’s because after running the crawl, you’ll need to perform a Crawl Analysis to populate it.
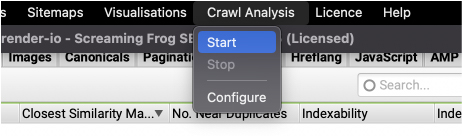
It will take a while, but you’ll see the report being filled as Screaming Frog finds the matches.
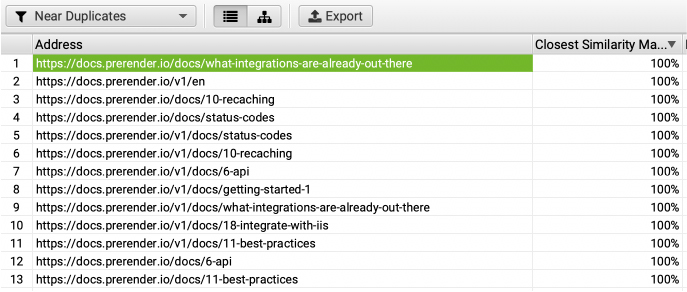
It also provides the percentage of similarity, and the Duplicate Details tab will provide us a snippet of the content of the pages compared side by side.

Something to keep in mind is that Screaming Frog is only pulling data from indexable URLs, so if you have canonicals in place, it will not add those pages to the reports, even if they are very similar pages.
In the majority of cases, that’s something we want. However, when we’re auditing for duplicate content, we can’t forget that having several pages with the same content is also a waste of the crawl budget.
If we want to optimize the crawl budget of our site by merging similar pages, all we need to do is go to configuration > content > duplicate content and uncheck the first option.
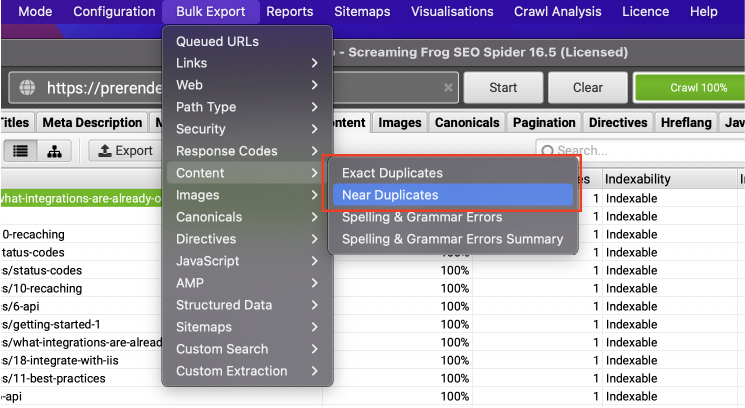
To pull the data, go to Bulk Export and choose each report.
3. Use Siteliner for a Quick Duplicate Content Analysis
For those just getting into the field or working with a reasonably small website (under 250 pages), you can use a tool like Siteliner.
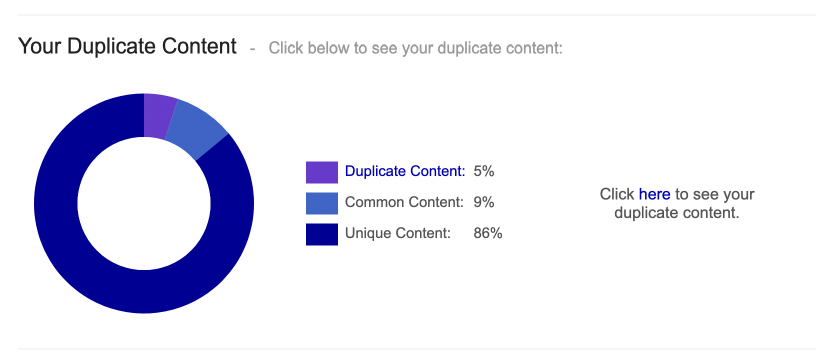
You can analyze your website once a month for free, and it’ll provide great insights into your duplicate pages and broken links and provide a comparison against similar sites.
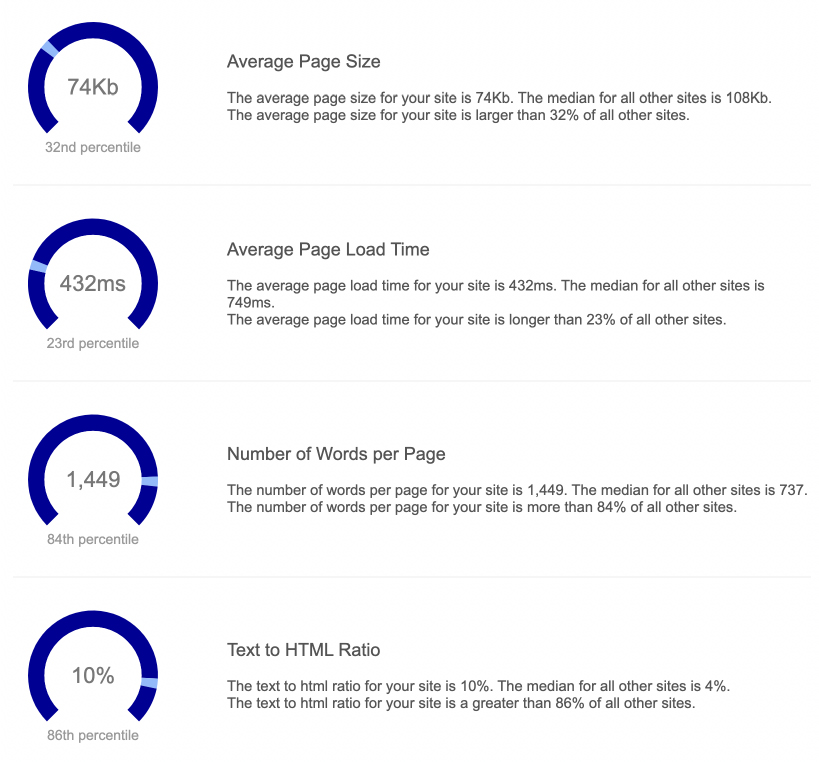
Although not directly related to duplicate content, it can help you find similar issues like thin pages or issues with page speed.
Inside the duplicate content report, the tool will provide you with the similarity percentage and how many pages match. You can export the data as a PDF or CSV file for further analysis.
7 Causes of Duplicate Content on Your Site and How to Fix Them

Now that we understand how to look for the data, it’s time to fix the problems and improve our SEO performance.
Many different things can cause duplicate content issues, and each one requires a different solution. To make it easier to understand, we’ll list the most common situations you’ll find and a solution for each.
If you can’t find a solution to your problem in this list or you think there’s one we should mention, please contact us on Twitter so we can add it to the list and help share the knowledge with the industry.
1. Several URL Versions Being Indexable and Accessible
One of the most common problems you’ll find are different versions of your URLs being accessible and indexed. In these cases, you can end up with people linking to your page from different versions – which is terrible for link equity.
Here are the three conventions you’ll work with:
- HTTP vs. HTTPS
- www vs. Non-www
- No trailing slash vs. trailing slash
The first one resolves itself as you should be using HTTPS, but the other two are more about preferences. The important thing is to keep it consistent throughout the entire website and create a 301 redirect from all other versions to the convention you’ll use.
Let’s use our site as an example:
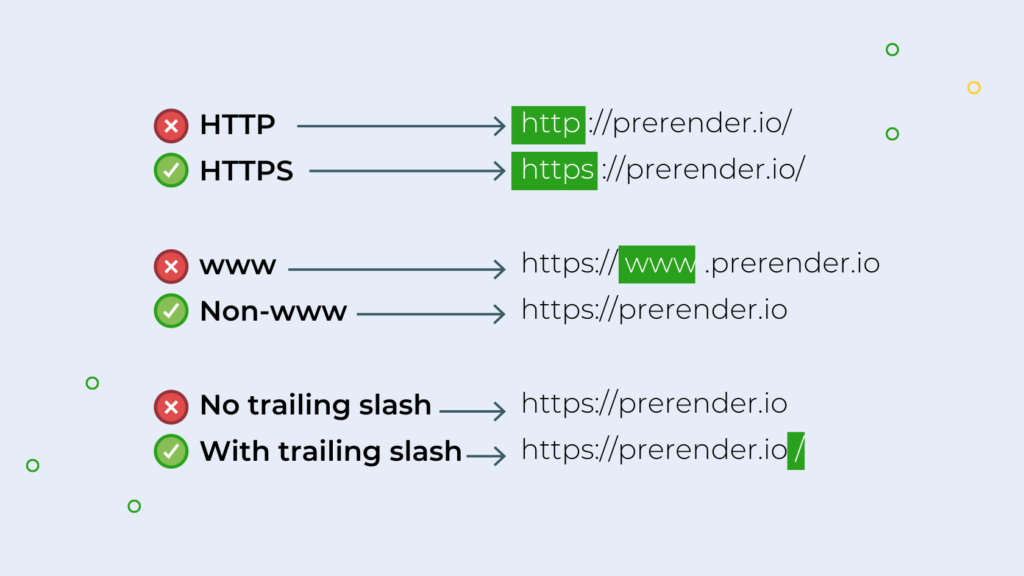
Nowadays trailing slashes don’t really matter that much and it’s more about personal preference. We like using the trailing slash as it feels cleaner, and it gives our writers a mental note, as they use them as an end period for URLs.
Note: Another common cause of duplicate content is using uppercase and lowercase letters in different moments for the same URL. URLs are case-sensitive, so you need to pick one convention and stick to it. Technically speaking, there’s no benefit in using one over the other, but it has become a standard to use lowercase letters for URLs.
2. URLs with Filtering Parameters Getting Indexed or Linked To
A typical issue you’ll find on many sites are filtering parameters in the URL as a result of a filtering feature that creates unique URLs for each query. It’s a tricky issue to deal with because we don’t want to hurt the user experience, but it can become a mess when you have a lot of visitors or filters.
Here’s an example from the crawl we ran before:

A simple solution for this problem is to set a canonical tag pointing to the original version of the page. It helps with authority, and it helps search engines decide which version to index.
If you also want to prevent these variations from getting crawled (because what’s the point), you can use your site’s robot.txt to prevent crawlers from crawling certain parameters.
For example, we could add the following snippet to our robot.txt file to block crawlers from accessing our signup page versions:
User-Agent: *Disallow: /*?plan=
Please note, the robot.txt file tells crawlers how to treat your website, so making a mistake here can have a heavy impact on your website. Without a clear understanding of how it works and an action plan, it’s better to keep away from it.
Here’s a great resource from Cloud Flare on how to use the robot.txt file. Read it before trying any idea out.
That said, the best way to prevent and solve this issue is building great faceted navigation.
Related: faceted navigation for ecommerce sites.
3. Complex Taxonomies Creating Redundancies
Site’s taxonomy refers to the different systems it uses to organize the content. Just for clarity, when we work with WordPress, we’ll notice two main taxonomies: category pages and tags.
A single article can be added to several categories and tags, and when you scale that to hundreds of pages, you can end up with many tags and categories displaying the same content over and over again.
These redundancies are a big source of duplicate content, and if these taxonomies are very distinct, it offers no user experience value, making them a double waste.
The best solution would be to streamline your site architecture, ensuring that content is added into a clearly-defined category. If a piece is shown into three or more categories, maybe your page is way too broad, and it would be better to break it down into smaller pieces that can then rank for unique topics.
However, we know that’s not always possible. Pick the main category for the page and make it the canonical version for those scenarios.
4. Localization and Hreflang
If we remember Google’s definition of duplicate content, we know that our English site and our Spanish site won’t clash with each other. The problem begins when we target different regions that speak the same language, using the same copy or just a few changes based on culture.
For these cases, Google uses the hreflang tag to understand how it should treat these versions. To avoid duplicate content, use this convention inside the head tag of your site:
<link rel="alternate" href="http://www.example.com" hreflang="en-us" />
<link rel="alternate" href="http://www.example.com/ireland" hreflang="en-ie" />
<link rel="alternate" href="http://www.example.com/uk" hreflang="en-gb" />
Example from SEO for Multi-Language Websites: hreflang tag guide
5. Content Distribution
Sometimes, we want our content to get more views through syndication: re-publishing it on other platforms or websites. Our article can be useful for someone else’s audience, and we can use the awareness to amplify reach. However, if this is done improperly, the second version of the article may rank on Google while ours (the original) stays in the dark.
To avoid this, add a canonical tag on your page to tell Google this is the original version of the piece and ask for your ally to do the same. If both pages point to the original, Google will understand which one to index and rank.
6. Generic Product Pages
Product pages are a big source of duplicate content. ecommerce sites can have hundreds or more products and, sadly, they are not always well optimized.
In fact, something we’ve seen a lot is that people use the same descriptions repeatedly – especially the manufacturer’s description – which creates unnecessary competition.
To stand out from the crowd, focus on writing unique descriptions and product pages for your products. Go the extra mile and write about customer experience, how it will feel to use the product, and maybe some use cases.
Writing unique copy for your product pages will differentiate you from the competition in the eyes of Google and your potential customers, so it’s a double win.
Related: how to optimize your product pages for search engines.
7. Landing Page A/B Testing
When running an ad campaign it’s important to perform A/B tests for optimization. These test versions of landing pages are not linked from anywhere on the site as they should only be reachable through an ad.
Nonetheless, Google and other search engines might still find and try to index these pages, and flag them as duplicate content – plus you can end up with one of these pages being indexed and potentially ruining the data. The same goes for A/B versions of a live URL.
For these pages it’s best to add a noindex tag to tell search engines to ignore it. After all, there’s no point in having them indexed and risking a technical issue for no reason.
Related: the impact of noindex and nofollow tags on your crawl budget.
How to Avoid Duplicate Content
So far we’ve discussed how to deal with duplicate content issues. Still, there’s no point in doing a full audit and technical optimization without creating a strategy to avoid this issue altogether in the future.
There are a few different things you can do to help avoid duplicate content at the front of your content strategy by creating certain rules and parameters:
- Run a Copyscape check for every new page and/or article. Sometimes pages around the same topic sound similar but there should always be some major differences.
- Provide the resources necessary to your writers to create unique, original content.
- Be more creative with product pages and avoid using the default description.
- Create a rule for handling URLs and make sure everyone involved with publications are aware of – and abiding by – it.
- Build and streamline your site’s taxonomies and how your webmasters handle them.
- When localizing your pages to other countries with the same language, make sure to add the necessary tags before publishing – if possible, make it into a checklist.
- Conduct regular site audits and keep your technical SEO in check. This is particularly important for JavaScript websites, which can result in a host of SEO challenges. One way to mitigate these problems is with a service like Prerender—watch the video below to see if it’s right for you.
Key Takeaways
- Duplicate content is harmful for your SEO, largely because of missed indexing and ranking opportunities.
- Avoid duplicate content by conducting frequent site audits, creating unique content and product pages, clearly handling URLs and communicating this to writers, streamlining site taxonomies, and keeping your technical SEO up-to-date.
- Common causes of duplicate content include: several URLs being indexable/accessible, URLs with filtering parameters being linked to, complex taxonomies creating redundancies, localization and hreflang, content distribution issues, generic product pages, and landing page A/B testing.
FAQs
Why is Duplicate Content Bad?
When search engines consider two or more pages to be duplicates, they choose the original and ignore the rest. If you have near or exact duplicates, you miss out on both pages being indexed. This can lead to missed ranking opportunities, poor user experience, backlink dilution, and keyword cannibalization.
How Do You Find Duplicate Content?
One way to find duplicate content is to use the Coverage report in Google Search Console and filter by “duplicate.” Another is to use Screaming Frog to check for exact or near duplicates. As well, most site audit features in SEO tools will highlight duplicate content.
How Do You Prevent Duplicate Content?
There are a few ways to do this. One is to keep your URL versions consistent (i.e., all HTTPS—not a mix between HTTPS and HTTP). You should also ensure your content is unique, such as avoiding repeating product descriptions for your ecommerce products. As well, add necessary tags before publishing multilingual content and frequently conduct regular site maintenance.
How Do You Avoid a Penalty for Duplicate Content?
Good news: there’s no official penalty for duplicate content—at least from Google. Google may issue penalties for plagiarism, but this isn’t the same as duplicate content. That being said, you still want to avoid duplicate content: search engines may filter duplicates out in SERPs, potentially harming your SEO performance.
Looking to improve your technical SEO? Start by optimizing your crawling and indexing performance with Prerender. Start with 1000 free renders today.