Before a website can rank for specific keywords, pages need to be indexed by search engines. But, before search engines can index those pages, they need to get discovered (the process of crawling).
In simple terms, crawling is when a bot follows a link to a page. Once it arrives on the page, it finds all the links on the page and follows them too. It’s an ongoing process, per page, but at some point, there’s a limit to the resources search engines possess. Google, Bing, and other search engines are forced to distribute these resources efficiency and smartly, so they set a crawl budget based on several factors.
For example, site architecture and page speed, to name a few.
So, without limiting your site’s performance potential, you need to try and optimize your site’s crawl budget so that you can count on more resources for Google to crawl and, subsequently, index all pages.
In this article, we’ll show you exactly how to do that. We’re going to focus on a different aspect of the crawling process: efficiency. For example, what it is, why it’s important (even for small to medium-sized websites), and how you can improve your crawl budget for JavaScript sites to gain an indexing advantage over your competition.
What is Crawl Efficiency?
As we’ve explored before, a crawled budget is the combination of the crawl rate limit (how fast Google’s crawler can crawl pages without overwhelming the server) and the crawl demand (the number of URLs Google visits in a single crawl).
Suppose we imagine a crawl budget as fuel: The crawl budget is the total amount of gas crawlers that have to work on our site. Of course, as the website grows to thousands or millions of URLs, we’ll need to make sure our crawl budget grows to ensure pages are getting discovered and (re)indexed.
Good to know: it’s not just about how much fuel we have but how we use it. If our crawl budget is wasted on irrelevant pages, managing redirections, or crawler traps, there’s no point in increasing it.
Make sense? So, when you optimize a site for crawl efficiency, you’re focusing on making the crawlers’ job easier, guiding them to the pages you most care about in terms of rankings.
How to Analyze Crawl Efficiency
There are three main ways to analyze crawl data to find issues or potential improvement opportunities:
Google Search Console’s Crawl Stats Report
To access GSC crawl stats, go to GSC > setting > Crawl Stats.
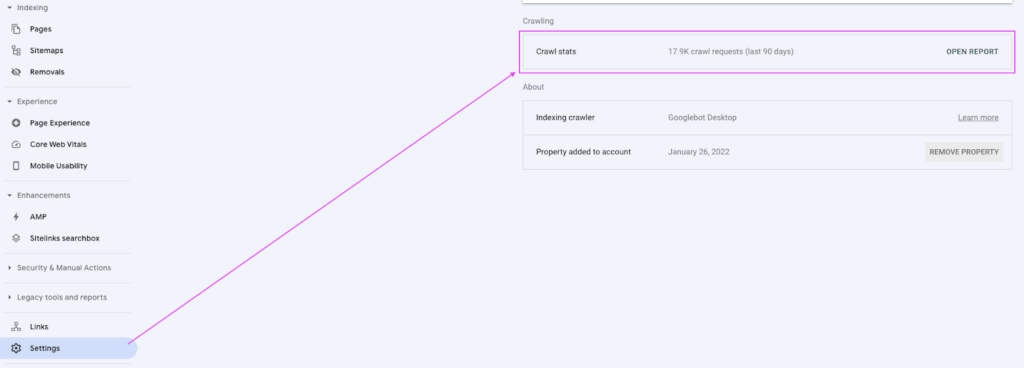
Here you can dive into different data sets like:
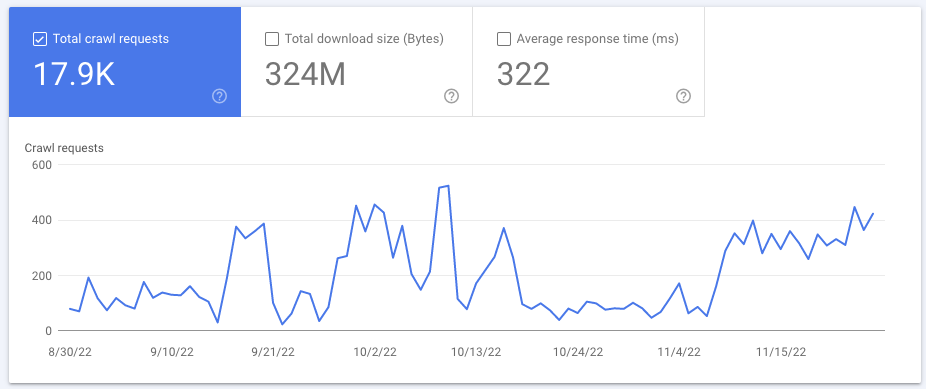
Total crawl requests:
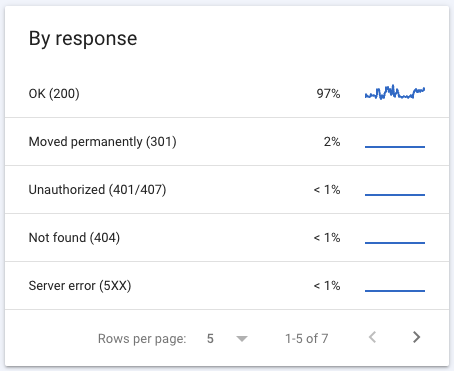
Crawl by response:
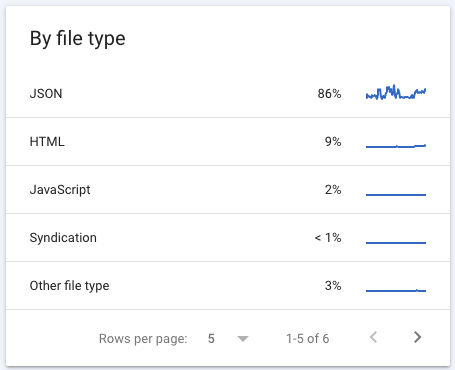
Crawl by file type:
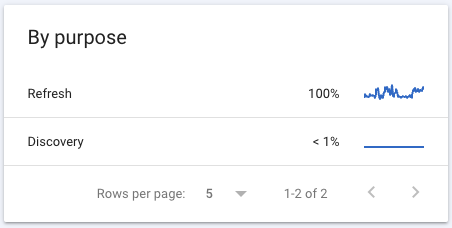
Crawl by purpose:
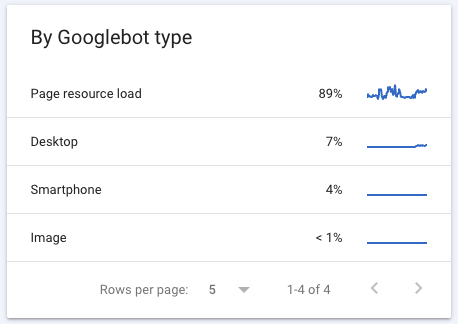
Crawl by Googlebot type:
Each report can provide you with insights into how Google is crawling your site.
For example, you can use the By File Type report to ensure most of the resources are going to valuable files like HTML instead of having all your budget go towards JSON data – like in the image above.
There are various crawling tools, such as Screaming Frog, designed with technical SEO in mind. These tools are great for creating a clear picture of what Google sees. By mimicking Googlebot, you can crawl your site/s and find useful insights about crawlability. For crawl efficiency optimization, focus on:
- Total pages crawled vs. the size of the site – if Screaming Frog (or any other tool you’re using) can’t find the page, it’s probable that Google won’t be able to either.
- The number of non-200 status response, non-indexable HTML pages, redirects, and redirects chains – these are pages consuming your crawl budget without any benefits.
- The number of paginated pages and canonicalized pages being crawled – make sure these are pages you want Google to crawl them.
Connecting the crawling tool to Google Analytics and Google Search Console’s API will provide more context to your analysis. For example, with GSC API connected, you’ll be able to crawl new URLs discovered in Google search console – by just ticking the box with the same name.
Data can be very overwhelming, but a good place to start to improve efficiency is how long it takes for Google to crawl a page after publication or after it’s been heavily updated.
The ultimate goal should be for:
- New pages to get discovered in a couple of days or, if possible, even hours
- Refreshed pages to be recrawled in a timely manner
- Pages constantly updating to be crawled at a higher rate than static ones
- Crawl resources prioritizing pages meant to rank rather than user-only, irrelevant, or broken pages
5 Steps to Maximize Crawl Efficiency
First, start by understanding the factors that impact your crawl budget. Some of the below recommendations will improve these factors. However, we’ve put more emphasis on efficiency.
1. Upgrade Your Servers/Hosting
Your site speed is important for both users and crawlers.
When the server has low response times (so it’s faster), crawlers can send more requests to download all necessary files like HTML, CSS, and JavaScript resources.
If the server starts to slow down, taking more and more time to respond as crawlers send requests (crawl limit), the crawl will slow down crawling or even stop altogether – which is actually a good thing, as it avoids crashing your site.
Check your hosting plan and make sure you have enough bandwidth and resources available based on how big your site is. The more pages you need search engines to crawl, the more hosting bandwidth you’ll need.
Pay attention to 5XX errors on your crawl reports. This could be an indication of connection timeouts or performance issues with your service.
2. Prerender Dynamic Pages
JavaScript complicates crawling because it demands an extra step in the process: rendering.
When a crawler accesses a page that requires JavaScript to render, it’ll send the page to the Renderer queue. Until this gets resolved, the crawler won’t be able to access the new links to follow. This interruption eats a big chunk of your crawl budget and slows down the whole process.
Plus, there’s no guarantee Google will be able to render it well, as many things can go wrong during this process; and that’s only Google. Search engines like Bing can’t handle JavaScript pages at all.
The best route to handle this issue is to take this workload out of search engines’ hands and use a solution like Prerender to create a static HTML (fully rendered) version of your dynamic pages and serve it to search engines instead.
By doing this, the response time will be near to instant on the second crawl onwards – as Prerender will use the first crawl after installation to generate the snapshot of your page – and ensure no content is missing.
Pro Tip: You can set Prerender to only pre-render crawlable and search visible pages, reducing the number of URLs you’ll cache. There’s no point in pre-rendering pages that won’t be indexed or crawled or functionality pages (like shopping carts) crawlers shouldn’t have access to.
3. Content Pruning
Just like pruning a tree, content pruning is the process of removing low-quality pages to improve the overall quality of your site. Every page on your website uses a portion of your crawl budget, and if a page is not adding any value to users, search engines, or potential customers, then there’s no point in keeping them on your site.
Here are a few suggestions to start your content-pruning process:
- If two or more pages talk about the same topic, and this topic is relevant for your site, merge them into one, 301 redirecting the least performer ones to the best URL and combining the content.
- Remove or update pages with outdated advice or information. If what the page says can’t be applied at all at this point in time, then this is, at best, outdated content and, at worst, misinformation. Make sure to remove all these pages to avoid hurting users.
- Pages that don’t receive traffic or are not ranking, and it’s obvious they never will, are good candidates for removal. If there’s an equivalent page, 301 redirect them to it before removing the page. If there’s not an equivalent page, then set a 410 Gone HTTP status code.
Removing a page should never be a quick decision. You need to plan and make sure the page is truly deadweight. A few questions to ask before hitting delete are:
- Is this page getting any traffic?
- Is this page relevant to users?
- Is this page relevant to potential users?
- Is this page getting backlinks? How Often?
- Is the content on the page useful?
- Are there other high-performing pages covering the same content?
If you answer these questions, you’ll make better decisions in the long run.
4. Use Directives Effectively
Using canonical tags, robot tags, and your robot.txt file are great ways to guide crawlers to your most important pages, but you need to understand how these affect crawling at large. Here are a few recommendations for using these directives to improve crawling efficiency:
- Don’t over-rely on canonical tags. Although these are great for avoiding indexing issues, they can be harmful to crawling if the number grows too big. Remember that once the crawler arrives at the canonicalized page, it will find the canonical link and also crawl that page. So for every canonicalized page, crawlers will crawl two pages. 100 canonicalized pages quickly become 200 crawls.
- “noIndex, noFollow” tags won’t stop search engines from crawling your pages but will slow them down. These tags are a clear signal for Google to deprioritize the crawling of these pages. After all, if they are not passing link authority and are not meant to rank, Google won’t feel the need to crawl them too often.
- Disallow folders and irrelevant (for search) pages. Blocking pages and resources you don’t want search engines to crawl will save crawl budget, but it won’t increase it. Some pages worth disallowing could be APIs, CDNs, infinite pages, and faceted pages.
Make sure that you’re only blocking pages that you will never want search engines to crawl and not just as a temporary measure.
Resource: Robot.txt Best Practices.
5. Prioritize Pages with Sitemaps
A well-optimized sitemap is crucial for crawling efficiency.
A sitemap provides Google with what you believe are the most important pages (for search) on your site.
Your sitemap must only contain pages that:
- You want Google to crawl and index
- Return a 200-code response
- Are the canonical version of the page
- Are relevant for your SEO strategy
- Pages that are updated somewhat frequently
You can also use sitemaps to add more context to your URLs, like setting localized versions of the URLs through Hreflang.
A healthy and updated sitemap can do wonders for your crawl efficiency.
Wrapping Up: Don’t Forget About Links
Although not always mentioned, a big part of crawl budget and crawl efficiency is page priority, which is closely related to the number of links pointing to the page.
External links are like votes of trust. These backlinks are a strong signal to Google that your page is relevant and trustworthy, as well as being a vehicle for Google to discover and crawl it.
You also can and should use internal linking intelligently to help search engines find your pages. Especially for large sites, internal linking is the perfect strategy to distribute authority from the “Homepage” (and highly linked pages) to content pages and pages lower in the site architecture.
Although some SEOs opt for flat site architectures – so every link is as close to the homepage as possible in the internal structure –the crucial aspect is how you’re linking your pages.
A great approach for this is using topic clusters, so thematic relevant pages link to each other. This not only helps Google find all of your pages, but it also tells Google the relationship between the pages and provides a strong signal about the topic/keywords you’re covering with them.
If you follow all these steps and best practices when optimizing your crawl budget, you’ll enjoy a healthier and more efficient crawl experience, and the results won’t take long to be seen.