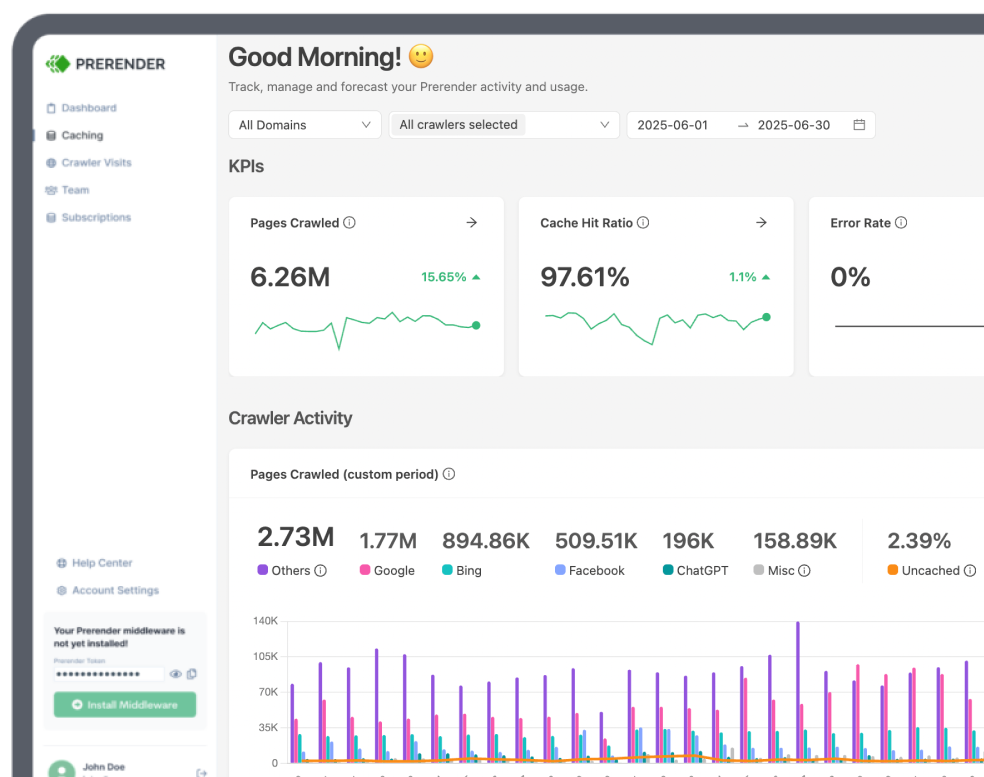
For large websites, getting discovered and indexed promptly by search engines can be challenging. Sadly, no matter how great your content is, if search engine crawlers can’t access and process your pages due to a depleted crawl budget, it won’t show up on the SERPs. This is why, smart crawl budget management is a must for enterprise-size websites.
This crawl budget guide shares some of the crawl budget best practices, focusing on newly emphasize website indexing strategies and practical tips based on the latest additions to Google’s workflows and documentation. You’ll discover how to reduce crawl waste, refine URL parameters, leverage separate subdomains for resource-heavy content, and more.
Why Are Large Sites More Vulnerable to Poor Crawl Budget Management?
Managing crawl budgets effectively becomes even more pressing when your site is massive. This is because the crawl budget doesn’t go proportionately with website sizes but is based on your website’s crawl rate and crawl demand.
-
- Crawl rate refers to the number of connections Googlebot can use to crawl your website. It is highly dependent on the speed of your servers.
- Crawl demand refers to how many pages Google wants and can crawl. It is highly dependent on your content quality, website popularity, and content update frequency.
Now, if you have a small website with static content, you’re likely to have plenty of crawl budget available for Google to effectively crawl and index the pages. However, if you have an ecommerce website with thousands of product pages but a slow server, poor content quality, but frequent content updates, your crawl budget is probably low and likely to be emptied out fast.
Need a refresher on the crawl budget role in content crawling and indexing? Our crawl budget optimization guide can help.
6 Best Practices to Optimize Crawl Budget Efficiency for Enterprise Websites

1. Minimize Crawl Budget Resource Usage for Page Rendering
The first and most crucial step in managing crawl budgets for large websites is ensuring crawlers quickly load and understand each page. There are a few strategies you can do:
- Prioritize critical rendering paths: delay non-essential scripts to load after the initial render to ensure above-the-fold content is displayed quickly.
- Optimize images: use next-generation formats like WebP and compress images to reduce file sizes without sacrificing quality. Head out to our media files optimization guide to learn how.
- Serve minified assets: deliver minified CSS and JavaScript files through a reliable CDN to decrease page load times.
- Bundle and chunk scripts: organize scripts so that each page loads only the resources it needs, minimizing unnecessary overhead.
2. Avoid Cache-Busting Parameters and Duplicate URLs
Nothing can inflate your indexable URL count and devour your crawl budget faster than random or unnecessary query strings. Cache-busting parameters (such as ‘?v=1234’ appended to CSS or JavaScript files) can create new URLs every time they change, potentially confusing search engines and prompting them to request the same resource repeatedly.
To avoid wasting your crawl budget on unnecessary URLs, keep your URL structure simple and consistent. Instead of using versioning in parameters like styles.css?v=2, include the version in the file name itself, like styles_v2.css.
Another smart practice is using canonical tags to tell search engines which version of a page or resource is the main one so they know exactly what to prioritize.
You can also use the “URL Parameters” tool in Google Search Console to manage how search engines handle certain parameters. These small changes can make a big difference by cutting down duplicate URLs, reducing confusion for crawlers, and helping your crawl budget focus on what matters.
Pro tip: while simplifying your site’s URL structure by removing cache-busting query strings is a good practice, thorough testing is crucial. Be aware of edge cases: some parameters do affect page content and should either be fully crawlable or consolidated with canonical tags.
3. Streamline Site Architecture and Navigation
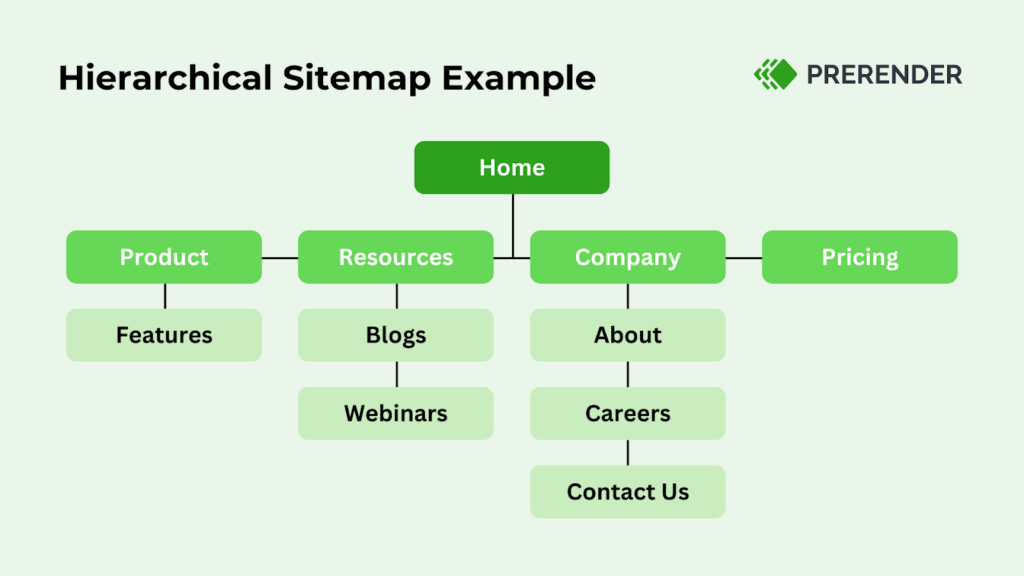
Optimizing crawl efficiency means keeping the structure of your site architecture as flat as possible so that Googlebot won’t spend a lot of crawl budget navigating through your pages.
When pages are logically organized and interlinked, search engine crawlers can quickly discover and revisit high-value content without wasting resources on complex crawling paths. This ensures that your crawl budget focuses on fresh or critical URLs rather than being wasted on low-value or duplicate pages.
Here’s a few pointers to keep in mind:
-
- Lean site structure: limit the number of clicks required to reach any critical page, ideally no more than two clicks from the homepage.
- Implement site breadcrumbs: use breadcrumbs to clearly show how pages fit into the site hierarchy, helping both users and crawlers navigate effectively without unnecessary detours.
- Set up hub pages: create hub pages for broad categories instead of cluttering the homepage with countless product or subcategory links. By consolidating related pages under these hubs, you guide crawlers toward the most important parts of your site and ensure they prioritize high-value content, maximizing your crawl budget’s impact.
4. Leveraging HTTP/2 and Server Push
Adopting HTTP/2 is a vital technical step for accelerating page load times for both end users and search engine bots. By enabling multiplexing, HTTP/2 consolidates multiple file requests—such as CSS, JavaScript, or images—into a single connection. This approach reduces latency and allows crawlers to process your site more efficiently, which is particularly beneficial if your pages rely on a large number of assets.
Complementing HTTP/2 multiplexing is Server Push, which proactively delivers critical resources to the client before they even need to request them. Though support and implementation details vary by browser and framework, Server Push can significantly decrease wait times.
Combining HTTP/2 and Server Push allows crawlers to quickly access and index your content, leading to a more efficient use of your crawl budget.
5. Keep Sitemaps Accurate and Up-to-Date
Sitemaps are essential for search engine optimization. They provide a clear structure, making it easier for search engines to find and index your content. This is particularly beneficial for large websites with numerous products or a large blog.
Google limits its sitemaps to 50 MB (uncompressed) and 50,000 URLs. This means that for enterprise-size sites, you’re likely to need to set multiple sitemaps, each dedicated to a specific section of the site, such as products, blog posts, or category pages. This segmentation helps search engines parse your sitemaps more efficiently and zero in on the most relevant areas of your site.
From a crawl budget management perspective, well-maintained sitemaps directly influence how efficiently search engines allocate their crawling resources. By keeping your sitemaps updated—ideally through an automated generation process that reflects any new pages or recent updates—you signal to search engines which URLs merit the most attention.
Submitting these up-to-date sitemaps to Google Search Console or other search engines helps prevent them from crawling outdated or irrelevant URLs, allowing more of your available crawl budget toward fresh, high-priority pages. This targeted approach ensures that crucial sections of your site get indexed promptly while low-value URLs are not repeatedly re-crawled.
Related: it’s recommended to audit and clean up your content from low-value pages. You don’t want your site to experience ‘index bloating.’ Learn more about what it is and how to mitigate this indexing issue here.
6. Adopt Prerender.io as a Sustainable Crawl Budget Management Tool
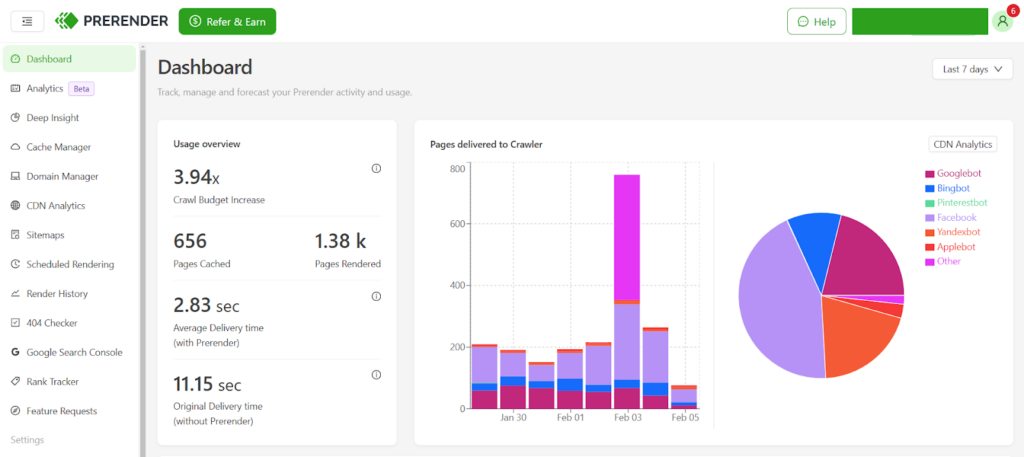
We’ve discussed several proven methods to optimize crawl efficiency for large websites. Although they work, you’ll need more effort to manually implement them and regularly monitor their progress. If you’re looking for a crawl budget solution that works more sustainably, Prerender.io is an excellent option.
Prerender.io is made to improve your JS crawling SEO performance by pre-rendering your JavaScript pages into their HTML version. That way, you free up Google from rendering and processing them, minimizing the amount of crawl budget they use to crawl and index your site on SERPs.
Does this mean Prerender.io is only suitable for static content? No. You can set up the cache intervals to match your content update needs. For instance, if you own an online shop in which products’ stock and prices change frequently, you can set up Prerender.io to re-render/re-cache these specific product pages every 24 hours. This allows Google to always pick up the latest update on your content and present it in the search results.
Other benefits of pre-rendering your JavaScript content include: faster indexing, better link previews, more visibility in AI search engine results, and the potential to mitigate sudden drops in traffic.
Want to see how else Prerender can help you improve your online visibility? Explore our case studies for real-world examples.
How to Check Your Site’s Crawl Budget Performance
Option 1: Manual Crawl Budget Site Audit with Google Search Console
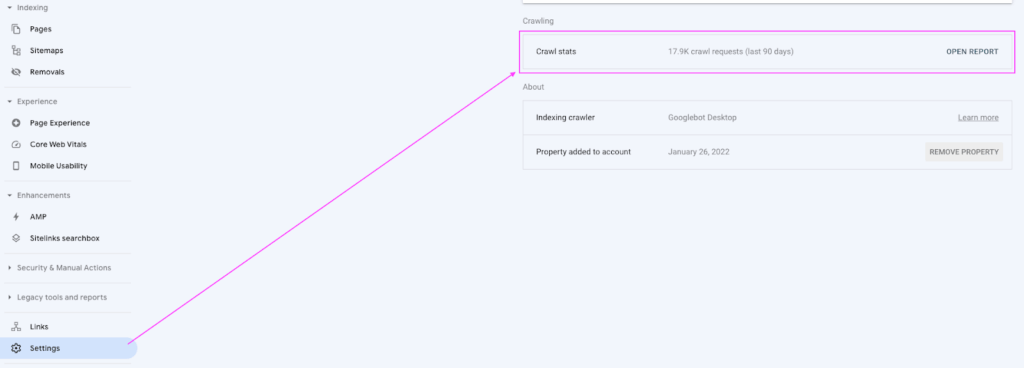
Google and other search engines don’t disclose how much crawl budget a website gets, but you can discover how many pages Google has crawled on your website to give you a ballpark figure.
To do this, log in to your Google Search Console account. Click on Settings > Crawling > Crawl Stats. You can see the number of pages Google crawled in the last 90 days. In the example below, Google crawled 17,900 requests in 90 days, or almost 199 pages per day.
Knowing your crawl budget number is gold for SEO success. It will tell whether your website suffers from a crawl budget deficiency (which may explain why it hasn’t reached its full potential). To check this, you also need to know how many pages you have on your website.
You can get this data from your XML sitemap. Run a site query with Google using ‘site:yourdomain.com,’ or use an SEO tool like Screaming Frog. Then, calculate your crawl budget efficiency using the following formula:
Total Number of Pages / Average Pages Crawled Per Day = Crawl Budget Efficiency
If the result is less than 3, your crawl budget is already optimal. If the result is higher than 10, you have 10x more pages on your site than what Google crawls per day. This means that crawl budget optimization is needed.
Disclaimer: The calculation provides a rough illustration of your crawl budget status, not an exact or official conclusion.
Option 2: Use Prerender.io Free Site Audit Tool
By analyzing the crawl data from Google Search Console (GSC) and comparing it with the pages listed in your XML sitemap, you can obtain a general estimate of your crawl budget’s health. This method, however, primarily monitors how your crawl budget is being spent.
For a more in-depth technical SEO audit that covers page delivery speed, indexing status, and Lighthouse performance metrics, use Prerender.io’s free site audit tool. Simply submit your website’s URL to Prerender.io, and you will receive a comprehensive technical SEO audit along with optimization recommendations via email. Take the first step to assess your site’s crawl budget health today!

Common Pitfalls in Crawl Budget Management
Even with the most carefully designed website indexing strategies, large websites can run into specific roadblocks that drain or misallocate their crawl budget. Here are some examples of it.
A. Over-Reliance on Robots.txt
Relying solely on robots.txt to manage crawling can lead to unintended consequences. When a URL has already been crawled or indexed, simply blocking it in robots.txt will not remove it from the index. Moreover, blocked pages may still appear in search results if there are external links pointing to them.

If you want to remove sensitive or obsolete pages from search results, it’s more effective to use the noindex directive or remove those pages entirely from your server. In other words, robots.txt is best used to block access to certain sections, such as admin folders or duplicate staging environments, but should not be the only line of defense for controlling which URLs appear in the index.
Related: How do noindex and nofollow affect crawling efficiency and SEO? Let’s examine the differences between noindex and nofollow.
B. Ignoring Mobile-First Indexing
With Google’s shift to mobile-first indexing, the mobile version of your site often determines how your content is crawled and ranked. Large sites that neglect mobile optimization may experience slow page loads or incomplete rendering on smartphones, limiting how efficiently crawlers can traverse the site.
If you want your site to perform better, ensure that your mobile pages mirror the content and functionality of your desktop site. Implement responsive designs, compress media for faster loading, and test mobile usability frequently. By providing a robust mobile experience, you help search engines crawl your site more effectively, ultimately preserving your crawl budget for pages with true ranking potential.
C. Mishandling Temporarily Unavailable Content
Large websites, especially ecommerce platforms, frequently deal with items going in and out of stock or seasonal pages appearing and disappearing. When these pages remain live but are effectively “dead ends,” crawlers may re-visit them unnecessarily.
One solution is to use appropriate HTTP status codes or structured data to indicate when content is no longer available. If the page is permanently gone, a 404 or 410 status code can let search engines know to remove it from active indexing.
However, if you plan to restock or reuse the page, consider adding clear messages for users while preserving essential metadata. Properly handling these temporary or seasonal pages prevents search engines from repeatedly crawling low-value or empty content.
Learn more about how to manage old content and expired listings for ecommerce SEO here.
Improve Your Crawl Budget Efficiency with Prerender.io
When dealing with SEO for large sites, crawl efficiency optimization is no longer optional—it’s the key to either thriving or failing in search rankings. Every bit of wasted crawl capacity is a missed opportunity for your key content to be discovered.
Focus on these strategies to maximize crawl efficiency and guide search engines to your key content: reducing resource consumption, simplifying site architecture, effectively managing URL parameters, and consistently updating sitemaps.
Another option is to use Prerender.io. This dynamic rendering JavaScript tool minimizes search engine crawlers’ excessive use of your valuable crawl budget. Having index-ready content also improves your server time for bots and crawlers and ensures Google picks up all your SEO and web page elements, boosting your page ranking.
Sign up for Prerender.io today to get started with a free 1,000 renders!
FAQs – Crawl Budget Management Best Practices
How Do I Know If I Have Crawl Budget Issues?
Check Google Search Console’s Crawl Stats report. Signs of crawl budget issues include:
-
- High number of unindexed pages
- Slow indexing of new content
- Excessive crawling of non-important pages
- Server errors during crawling
How Does JavaScript Affect Crawl Budget Consumption?
JavaScript execution consumes more crawl budget because additional resources need loading, API calls require extra processing, and DOM updates need more rendering time.
How Can Prerender.io Help With Crawl Budget Optimization?
Prerender serves pre-rendered HTML versions of your JavaScript pages to search engines, making crawling more efficient. This helps reduce server load, speed up crawling, improve indexing efficiency, and maximize crawl budget usage. This also helps you save on costs compared to in-house server-side rendering.
Interested in further reading? You might also enjoy: