Enterprise-level websites often struggle with crawl budget management, which hinders search engines like Google from timely indexing new content. Effective crawl budget optimization is, therefore, essential to ensure your pages appear in search results.
This crawl budget guide will teach you how to efficiently identify and optimize pages that consume a lot of crawl budget within your large-scale website. By pinpointing these resource-intensive pages, you can allocate a crawl budget more effectively and improve your website’s overall search engine visibility and SEO rankings.
5 Most Common Pages That Deplete Your Crawl Budget
Here are five types of pages that can easily drain your crawl budget.
1. Soft-404 Errors
Soft 404 errors occur when a page no longer exists (so it should be displaying a 404 not found error) but appear to exist because the server returns a 200-ok status code or it’s displaying content that shouldn’t be there anymore.
This error is a mismatch between what the search engine expected and what the server returns.
For example, another way it can happen is if the page is returning a 200 status code, but the content is blank, from which search engines would interpret it as actually a (soft) 404 error.
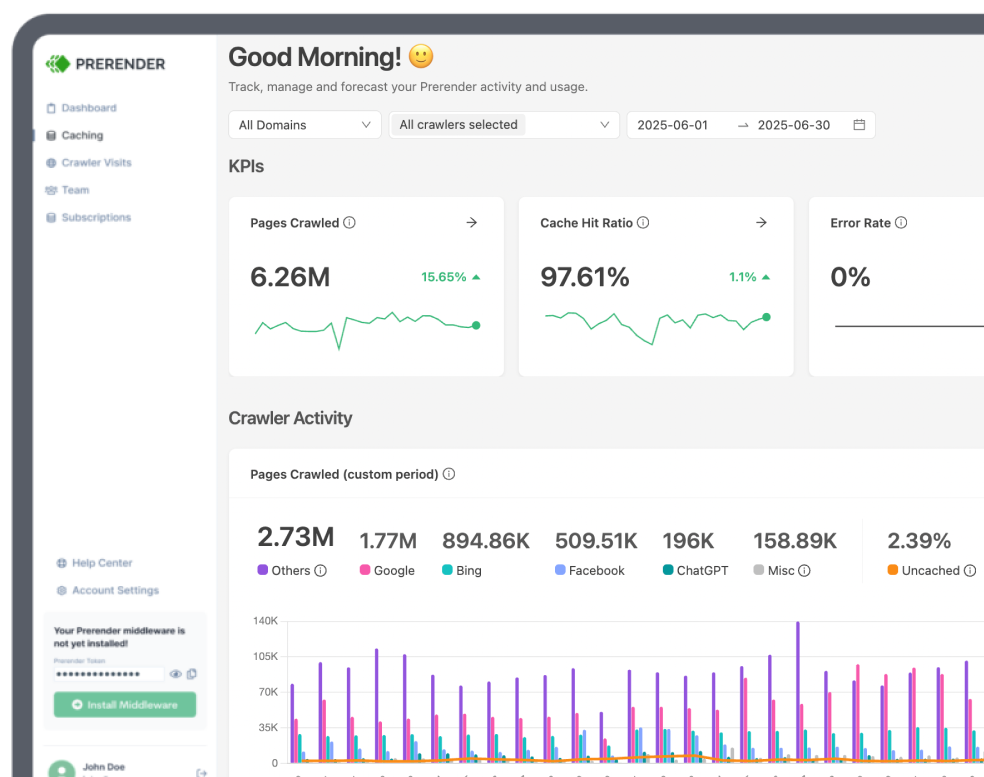
Finding these pages is actually quite simple because Google Search Console has a specific soft 404 error report.
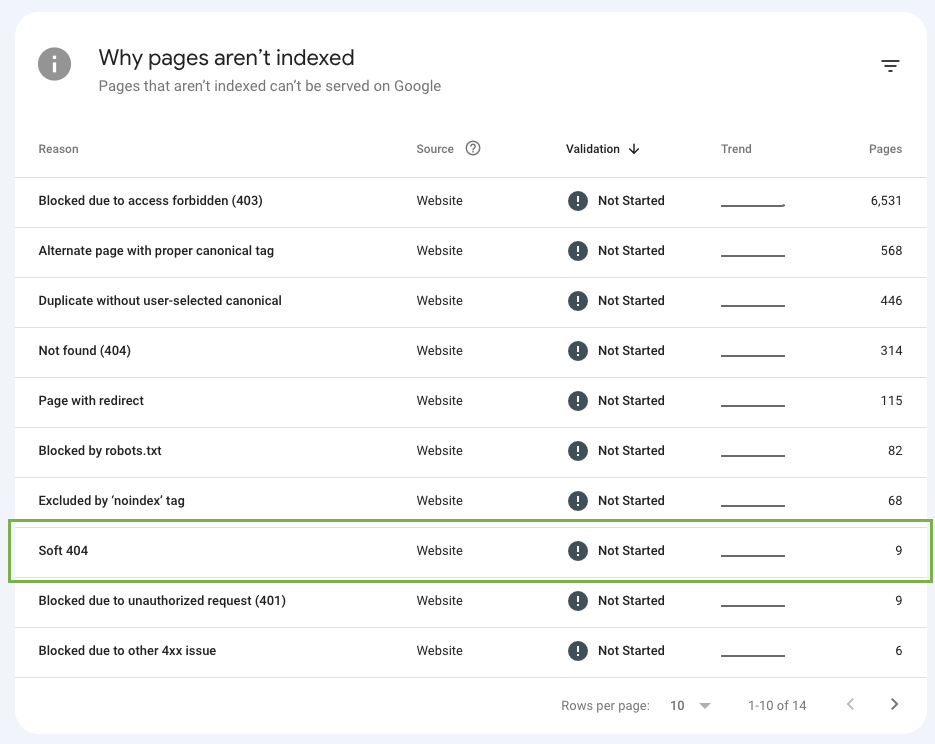
Although crawlers will eventually stop crawling pages with a “Not found (404)” status code, soft 404 pages will keep wasting your crawl budget until the error is fixed.
Note: It’s a good idea to check your “Not found (404)” report and make sure that these pages are returning the correct status code, just to be sure.
For a more detailed step-by-step guide, follow our tutorial on how to fix soft 404 errors.
2. Redirection Chains
A redirection chain is created when Page A redirects to Page B, which then redirects to Page C, and Page C redirects to Page A, forming an infinite loop that traps Googlebot and depletes your crawl budget.
These chains usually happen during site migrations or large technical changes, so it’s more common than you might think.
To quickly find redirect chains on your site, crawl your site with Screaming Frog and export the redirect chain report.
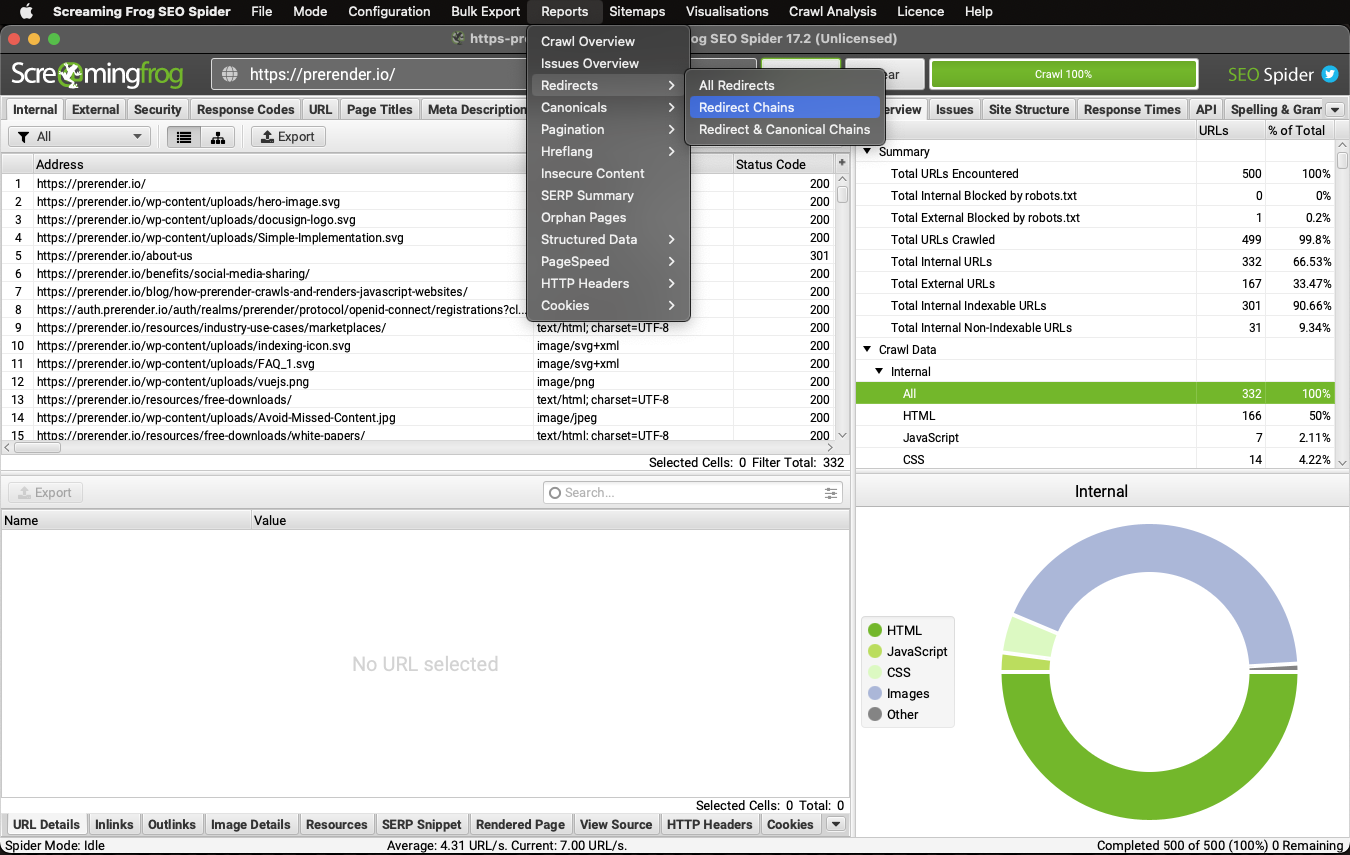
However, crawling your entire site would require a lot of storage and resources from your machine to handle.
The best approach is to crawl your site using the sections you already created. This will take some of the pressure off your machine as well as reduce the amount of time it would take to crawl millions of URLs in one go.
Note: You have to remember that Screaming Frog will also crawl resources like JS files and CSS, taking more time and resources from your machine.
To submit a list for Screaming Frog to crawl, switch to List Mode.
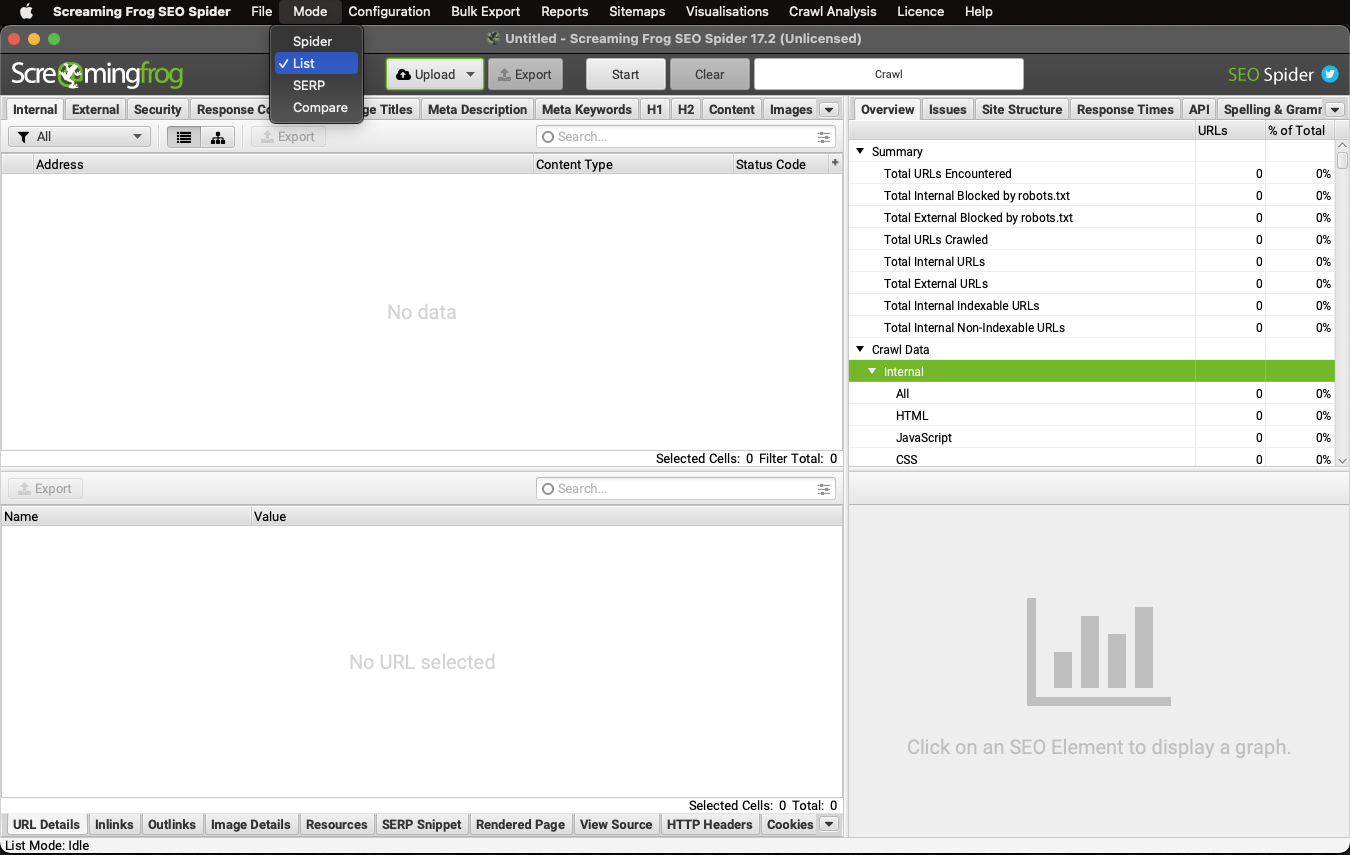
Follow our tutorial on fixing redirect chains for clear step-by-step instructions.
3. Duplicate Content
According to Google, “duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content in the same language or are appreciably similar.”
These pages can take many forms like faceted navigation, several URL versions being available, misimplemented Hreflang alternate URLs for localization, or just generic category templates showing almost the same content.
Because Google perceives them as essentially the same page, it will crawl all of these pages but won’t index them or treat them as spam and hurt your overall SEO scores.
In terms of crawl budget, all of these pages are taking resources away from the main pages on your site, wasting precious crawling time. This gets even worse if the pages flagged as duplicate content require JavaScript rendering, which will 9X the time needed to crawl them.
The best way to find duplicate pages is by checking Google Search Console’s “duplicate without user-selected canonical” report, which lists all the pages Google assumes are duplicated pages.
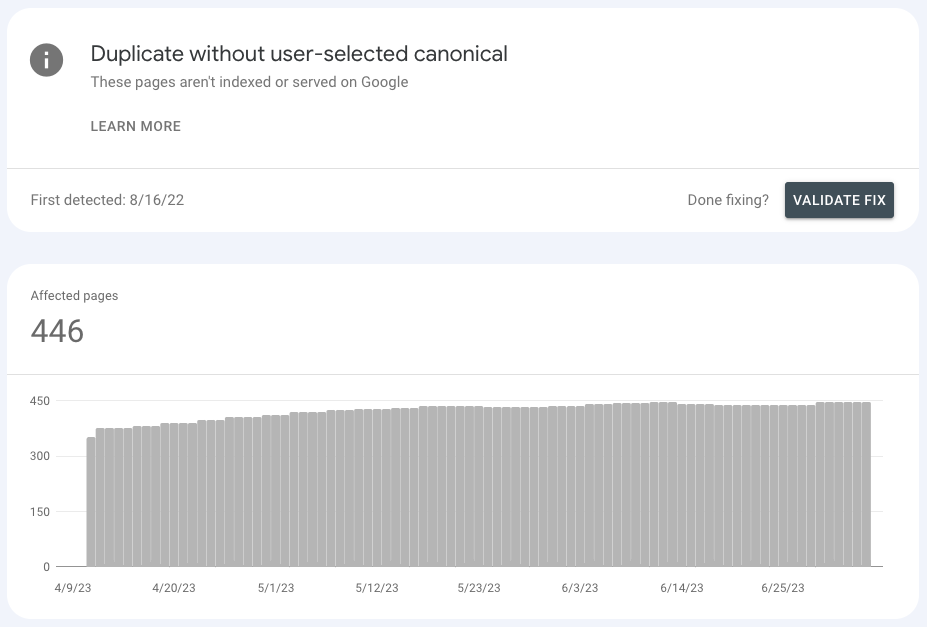
You can contrast this information with Screaming Frog by crawling your site locally and then checking the “near duplicate” report.
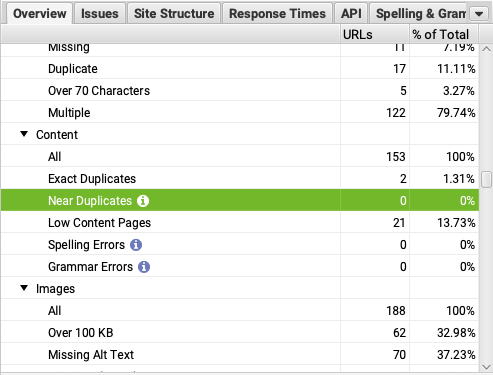
Check our guide on fixing duplicate content issues for a step-by-step tutorial.
4. Slow or Unresponsive URLs
If we understand crawl budget as the number of HTTP requests Googlebot can send to your website (pages crawled) in a specific period of time (crawling session) without overwhelming your site (crawl capacity limit), then we have to assume page speed plays a big role in crawl budget efficiency.
From the moment Google requests your page to the moment it finally renders and processes the page, we can say it is still crawling that URL. The longer your page takes to render, the more crawl budget it consumes.
There are two main strategies that you can use to identify slow pages:
A.) Connect PageSpeed Insights with Screaming Frog
Screaming Frog allows you to connect several SEO tools APIs to gather more information from the URLs you’re crawling.
Top tip: Not a fan of Screaming Frog? Discover 10 paid and free alternatives to Screaming Frog to support your technical SEO auditing needs.

Connecting PageSpeed Insights will provide you with all the performance information at a larger scale and directly on the same crawl report.
If you’ve already crawled your site section, don’t worry, Screaming Frog allows you to request data from the APIs you’ve connected retroactively. Avoiding you the pain of crawling thousands of URLs again.
 B.) Identify slow pages through log file analysis
B.) Identify slow pages through log file analysis
 B.) Identify slow pages through log file analysis
B.) Identify slow pages through log file analysisLog files contain real-life data from your server activity, including the time it took for your server to deliver your page to search engines.
The two metrics you want to pay attention to are:
- Average Bytes – the average size in bytes of all log events for the URL.
- Average Response Time (ms) – The length of time taken (measured in milliseconds) to download the URL on average.
As a benchmark, your pages should completely load in 2 seconds or less for a good user experience, but Googlebot will stop crawling any URL with a server response longer than two seconds.
Here’s a complete guide to page speed optimization for enterprise sites you can follow to start improving your page performance on both mobile and desktop.
5. Pages with No Search Value in Your Sitemap
Your sitemap acts as a priority list for Google. This file is used to tell Google about the most important pages on your site that require its attention.
However, in many cases, developers and SEOs tend to list all URLs within the sitemap, even those without any relevancy for search.
It’s important to remember that your sitemap won’t replace a well-planned site structure. For example, sitemaps won’t solve issues like orphan pages (URLs without any internal links pointing to them).
Also, just because a URL is in your sitemap doesn’t mean it’ll get crawled. So, you have to be mindful about what pages you’re adding to the file, or you could be taking resources away from your priority pages.
Here are the pages you want to identify and remove from your sitemap:
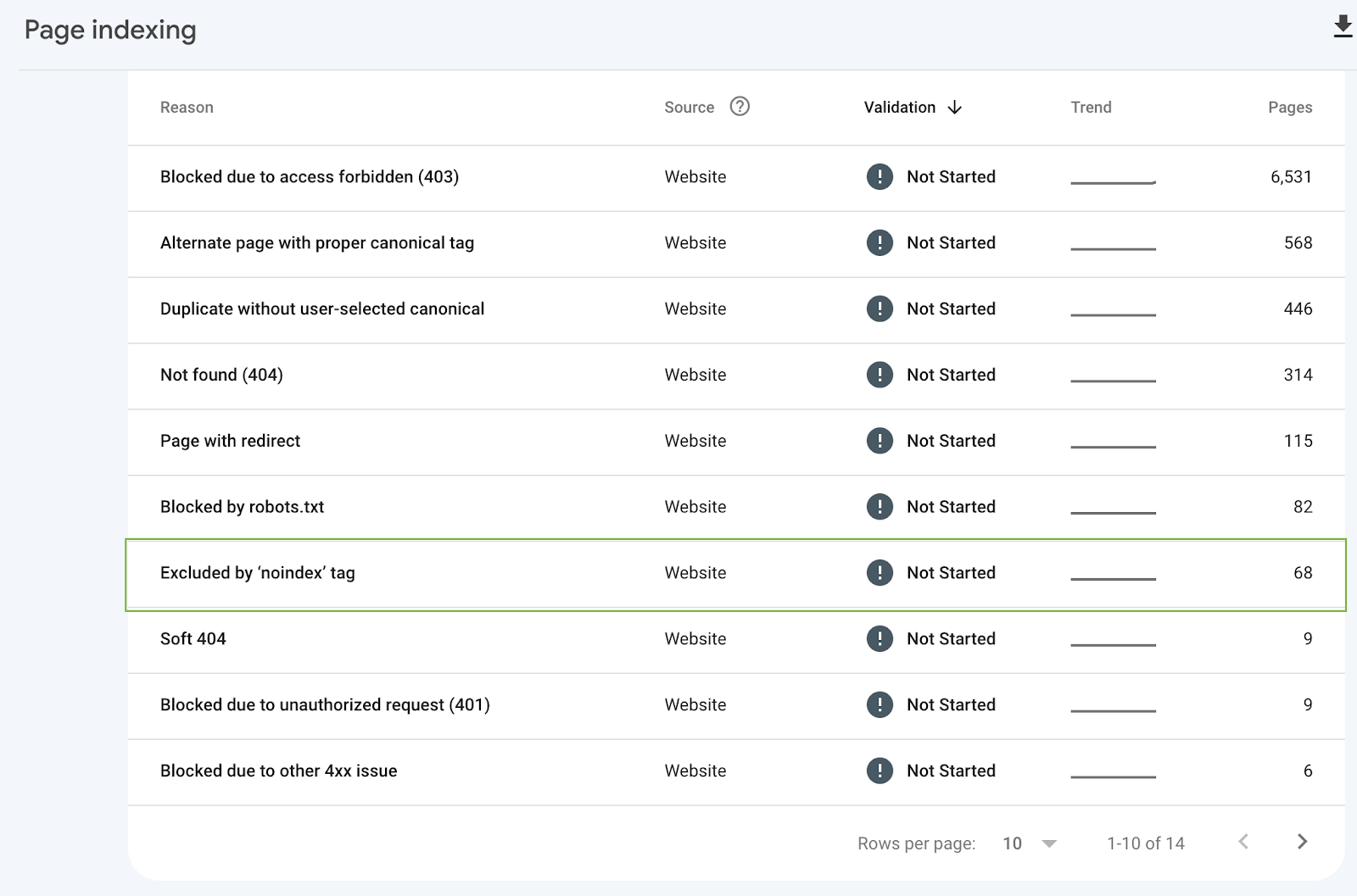
I.) Pages Tagged as Noindex
This tag tells Google not to index the URL (it won’t show in search results), but Google will still use the crawl budget to request and render that page before dropping it due to the tag.
If you’re adding this URL to your sitemap, you’re wasting crawl budget on pages that have no search relevance.
To find them, you can crawl your site using Screaming Frog and go to the directive report:
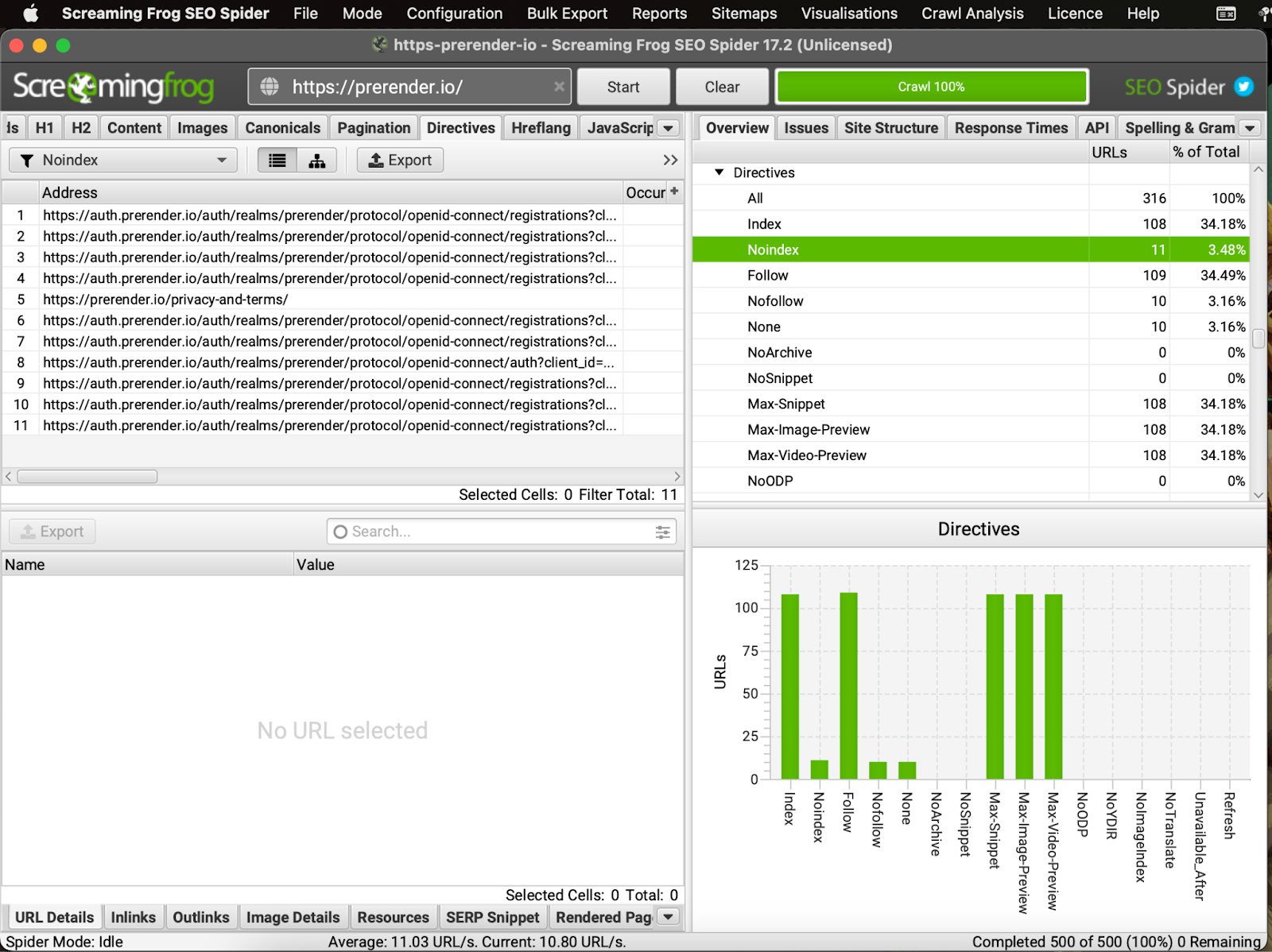
You can also find these pages in the Search Console’s indexing report.
II.) Landing Pages and Content Without Ranking Potential
There are landing pages and content that just won’t rank, and from millions of URLs, you are bound to have a few of those.
It doesn’t mean there’s no value in having them indexed. It just means there’s no value in having them discovered through the sitemap.
Your sitemap should be a curated list of highly valuable pages for search. Those that move the needle in traffic and conversions.
A great way to find underperforming pages at scale is by connecting your Google Analytics and Search Console directly to Screaming Frog. This will allow you to spot pages with zero rankings quickly.
You can also connect Ahrefs’ API to get backlink data on the URLs you’re analyzing.
III.) Error Pages, Faceted Navigation, and Session Identifiers
It goes without saying, but you also need to clean your sitemap from any page returning 4XX and 5XX status codes, URLs with filters, session identifiers, canonicalized URLs, etc.
Note: You don’t need to block canonicalized pages through the Robot.txt file.
For example, adding the entire pagination of a product category is not valuable. You only need the first page, and Google will find the rest while crawling it.
You’ve already found most of these pages in the previous steps. Now check if any of them are in your sitemap and get them out.
Challenges Crawl Budget Optimization for Enterprise Websites
Although enterprise sites must follow the same best practices as any other type of website, enterprise sites represent a unique challenge because of their large scale and complex structure. To ensure we’re on the same page, here are the three main challenges you’ll encounter during your enterprise crawl budget optimization process:
A High Number of URLs
One common denominator among enterprise sites is their size. In most cases, enterprise websites have over 1M URLs, making it harder for any team to stay on top of each and every one of them. Plus, it also makes it easy for teams to overlook some URLs and make mistakes.
Deadlines and Resources
Something that’s very common in this kind of project is having unrealistic deadlines with limited resources. These resources are both time, people, and tools. Crawl budget optimization is a highly technical and collaborative endeavor, and for teams to be able to manage it successfully, they need to automate certain tasks with tools, count with different experts like writers, SEOs, and developers, and have enough time to implement safely.
Implementation and Testing
Connected to the previous point, teams usually don’t have enough time for testing, which can have terrible results if your teams have to rush through implementation. Because of the complex structure of your site, even a small change might affect hundreds or thousands of URLs, creating issues like rank drops.
That said, making changes to your site shouldn’t be scary as long as you develop a solid plan, provide the right resources (including time, tools, and experts), and be conscious that testing is a necessary part of the process to avoid losing traffic and conversions.
3 Tips to Plan Your Enterprise Crawl Budget Audit
Every plan has to be tailored-made to fit your own organization, business needs, and site structure, so there’s no one-fit-all strategy you can find online.
Still, there are three simple tips you can use to make your crawl budget audit easier to manage and implement:
1. Find a Logical Way to Break Down Your Site
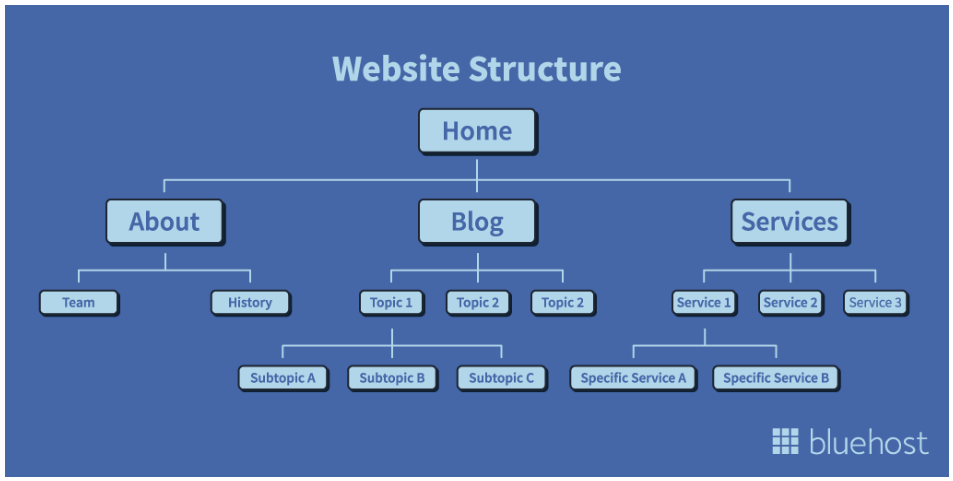
You can group similar pages following your website structure (which is the hierarchical order pages are linked between each other in relation to the homepage), creating individual sections that are easier to understand and evaluate.
Because every website has a unique structure, there isn’t a single best way to separate every site. Nevertheless, you can use any of the following ideas to get started:
- Group your pages by type—not all pages are built equally, but there are groups of pages sharing a similar approach. For example, your main landing pages might use the same template across all categories, so evaluating these pages together will give you insights into a bigger portion of your site faster than analyzing them one by one.
- Group your pages by cluster—another way to do this is to identify topic clusters. For example, you might have category pages, landing pages, and content pages talking about similar topics and, most likely, linking to each other, so it makes sense for a team to focus on the whole.
- Group your pages by hierarchy—as you can see in the image above, your structure has a “natural” flow based on how you’ve structured your website. By building a graphical representation of your pages, you can separate the different sections of your pages based on this structure – however, for this to work, your website needs a clear structure, if it doesn’t, it’s better to go with any of the previous ideas.
2. Delegate Each Site Section to an SEO Team
Once you know how you want to divide your website, it’s time to get all URLs into a central spreadsheet and then allocate each site section to a particular team – you can copy all the URLs assigned to a team into a different spreadsheet.
When we talk about teams, we don’t necessarily mean having three different experts per section of your page—although that would be ideal.
Instead, you’ll want to have one SEO professional for each section of the site do the audit. These professionals will provide all the guidelines, assign tasks, and oversee the entire project.
For technical optimization like page speed, you’ll want one or two dedicated developers. This will ensure that you’re not taking time away from the product.
Lastly, you’ll want at least two writers to help you merge content where needed.
By creating these teams, you can have a smoother process that doesn’t take resources from other marketing areas or engineering. Because they’ll focus solely on this project, it can be managed faster.
3. Start Testing
You can use a project management tool like Asana or Trello to create a centralized operation that allows data to flow throughout the project.
Once the first tasks are assigned (implementation tasks), it’s important to give a testing period to see how changes affect your rankings. In other words, instead of rolling all changes at the same time, it’s better to have a couple of months to take a small sample of URLs and make the changes.
If the effects are negative, you’ll have the time to reverse the changes and study what happened without risking the entire site.
A Better Crawl Budget Management for Your Large-Scale Websites
Rendering has a direct impact on your crawl budget and is arguably the biggest. When Google finds a JS file within a page, it’ll need to add an additional rendering step to access the entire content of the URL.
This rendering step makes the crawling process take 9x longer than HTML static pages and can deplete your crawl budget between just a few URLs, leaving the rest of your site undiscovered.
Furthermore, many things can go wrong during the rendering process, like timeouts or partially rendered content, which create all sorts of SEO issues like missing meta tags, missing content, thin pages, or URLs getting ignored.
To find these pages, you’ll need to identify all URLs using JS to inject or modify the pages’ content. Most commonly, these are pages showing dynamic data, product listings, and dynamically generated content.
However, if your website is built using a JavaScript framework like React, Angular, or Vue, you’ll experience this rendering issue across the entire site.
The good news is Prerender can solve all rendering issues from its root, increase crawl budget, and speed up the crawling process with a simple plug-and-play installation.
Prerender crawls your pages and generates and caches a 100% index-ready snapshot – a completely rendered version – of your page.
When a search engine requests your URL again, Prerender will deliver the snapshot in 0.03 seconds, taking the rendering process off Google’s shoulders and allowing it to crawl more pages faster.
Explore more about crawl budget optimization: