Can you guide Google crawlers in prioritizing crawling specific URLs? Yes, you can. This is a smart technical SEO strategy to use if you want to manage your crawl budget spending better so you can prioritize indexing content that impacts your bottom line.
We’ll first discuss crawl efficiency and how to leverage sitemaps to let Googlebot crawl specific URLs of your website, breaking down the fundamentals step-by-step. Then, we’ll talk about how to improve your crawling performance, exploring both reactive solutions (such as identifying and removing low-value pages) and proactive strategies (such as pre-rendering).
1. Increase Your Crawl Efficiency
The first thing you can do to guide Googlebot discover and crawl specific pages is to increase your crawl efficiency.
Crawl efficiency refers to the effective use of your crawl budget. It heavily influences the way Google discovers and indexes your new or updated content.
Note: Crawl efficiency differs from crawl budget—the amount of resources that Google allocates to each website to crawl and index its content. If you need a refresher, this FREE crawl budget whitepaper will help you.
Related: Learn how to optimize your crawl budget to maximize your SEO impact.
Here are some other factors that influence crawl efficiency.
1A. Understanding Crawl Rate Limits
According to Google, the crawl rate limit is the “maximum fetching rate for a given site.” It’s not a fixed number; Google sets it based on factors like your server’s health and how you use redirects.
A healthy server with minimal errors welcomes Googlebot with a higher crawl rate limit, allowing it to explore more of your website. But be mindful of redirects! While they’re helpful for moved content, excessive redirects can quickly deplete your crawl budget.
This is because every redirect Googlebot encounters takes an extra crawl. Optimizing your redirects helps. Update navigation links directly to the new URL instead of relying on redirect chains.
Keep in mind that Googlebot prioritizes fresh content. Regularly updated websites signal to Googlebot that they need to crawl more frequently. This can lead to an adjustment in your crawl rate limit.
By optimizing redirects and keeping your content fresh, you ensure Googlebot efficiently explores your website and discovers your most valuable content.
1B. Structure and Content for Efficient Crawling
A well-structured website with clear internal linking is like a well-organized library. It acts as a roadmap for Googlebot, guiding it to the most important pages and minimizing wasted time on low-value ones.
Here’s how to optimize your website structure for efficient crawling:
- Clear internal linking: Strong internal links act as arrows, pointing Googlebot in the direction of your most valuable content. This ensures Googlebot discovers and indexes your important pages effectively.
- Strategic use of robot meta tags: Robot meta tags like noindex or nofollow provide even more control over how Googlebot crawls your site. For example, if your blog relies on category pages for organization, using nofollow on the main blog page tells Googlebot to prioritize the category pages for indexing, giving it more context for your blog posts. But remember, proper linking to category pages is still crucial for this strategy to work.
- Clean and logical URL structure: Clear URLs that accurately reflect their content are like labeled shelves in a library. They help Googlebot understand and index your pages efficiently.
1C. Identify and Remove Low-Value Pages
Low-value pages typically include outdated promotions, thin content with minimal or no value, duplicate content resulting from URL parameter issues, and dynamically generated pages that don’t offer unique value. When Googlebot spends its time crawling these pages, your crawl budget is quickly exhausted. We’ll discuss this in more detail in the next sections.
2. Use Sitemap to Highlight Googlebot Your Important Pages
Your sitemap.xml file serves as a roadmap to your site’s most critical pages for Googlebot. However, there’s a trove of opportunities lying beneath the surface that can be harnessed to maximize your crawl budget. (*Note that sitemaps are particularly crucial for large websites, new websites, sites with large archives, or sites using rich media or appearing in Google News.) In these cases, a well-structured and regularly updated sitemap.xml file can significantly enhance crawl efficiency.
2A. Effective Use of XML Tags
XML tags can serve as guiding beacons for Googlebot. For instance, the <priority> tag allows you to indicate the importance of each page relative to other pages on your site. This doesn’t necessarily guarantee these pages will be crawled more often, but it signals to Googlebot which pages you deem most important.
The <lastmod> tag is another useful tag, as it provides Googlebot with the date a page was last modified. As Googlebot prefers fresh content, making regular updates and correctly utilizing the <lastmod> tag can attract more crawls to your important pages.
It’s also possible to include more than URLs in your sitemap. By incorporating media such as images and videos using <image:image> and <video:video> tags, you can enhance Googlebot’s discovery and indexing of these resources. This can be especially useful if your site relies heavily on rich media to engage users, or if you’re using Javascript to load images after the page has rendered, as Google won’t see those.
2B. Structure Your Sitemap
A single sitemap.xml file can contain up to 50,000 URLs, but this doesn’t necessarily mean you should aim to reach this limit. Overloading your sitemap could potentially lead to slower load times and an inefficient crawl. Keep your sitemap lean and focused on your most important pages to ensure optimal crawl efficiency.
Consider segmenting your sitemap by content type, such as blog posts, product pages, and others. For larger sites boasting numerous sitemaps, a sitemap index file is often preferred. A sitemap index file is essentially a sitemap of sitemaps, allowing you to neatly organize your multiple sitemaps and guide Googlebot through them effectively. This ensures even your largest websites are crawled and indexed efficiently.
2C. Test Before You Submit Your Sitemap
Lastly, always remember to test your sitemap for errors using Google Search Console before submitting it. This preemptive measure can save you from potential pitfalls down the line and ensure Googlebot can crawl your sitemap as intended.
3. Use Robots.txt to block Google from Crawling
Unlike using sitemap to Googlebot to your important pages, using robots.txt and ‘disallow’ rules blocks Google crawlers visiting certain pages on your site. This strategy is intended to save your limited crawl budget from being used to crawl and index unimportant pages, and allocate the budget for your bottom-line content.
Go to this detailed guide on how to use robots.txt to start using this technique.
P.S. The blog also includes some do’s and don’ts, as well as other best practices that you don’t want to miss!

4. Improve Your Crawling Performance
4A. Leverage Google Search Console
Google Search Console is a free service offered by Google specifically for website owners and developers. It provides a comprehensive suite of tools to help you monitor and optimize your website’s performance in Google Search results.
Here’s a breakdown of what Google Search Console can do for you:
- Monitor crawling and indexing: Track how Google crawls and indexes your website’s content. This allows you to identify any potential issues that might prevent your website from appearing in search results.
- Fix crawl errors: Identify and troubleshoot crawl errors that might be hindering your website’s visibility. These errors could be broken links, server issues, or problems with robots.txt files.
- Submit sitemaps: Easily submit your website’s Sitemap to Google. A Sitemap is a file that lists all the important pages on your website, helping Google understand your website structure and content.
- Analyze mobile usability: Test how mobile-friendly your website is. With the increasing number of mobile users, ensuring a seamless mobile experience is crucial.
- Improve search ranking: By addressing crawl errors, optimizing website structure, and ensuring mobile-friendliness, you can improve your website’s ranking in Google Search results, potentially leading to more organic traffic.
4B. Monitor Your Crawl Stats in Google Search Console
Google Search Console’s Crawl Stats data gives you a window into how Googlebots interact with your website. Here are two key metrics to watch:
- Pages crawled per day: This shows how often Googlebots visit your site. Significant changes might indicate issues or the impact of recent updates.
- Average download time: This measures how long it takes Googlebots to download your pages. A sudden increase could point to performance problems hindering efficient crawling.
By monitoring these metrics, you can identify potential roadblocks and ensure Googlebots can crawl your website smoothly.
4C. Check Crawl Errors
Crawl errors are roadblocks that prevent search engine crawlers from accessing and indexing your website effectively. By understanding and fixing them, you can improve your website’s visibility in search results.
Common crawl errors:
- Server errors: When a server fails to respond to Googlebot’s requests, it results in server errors. These can be caused by server issues, DNS problems, or downtime.
- Soft 404 errors: These occur when a page displays a “page not found” message but returns a success code (200) instead of a proper 404 code. This confuses search engines and hinders indexing.
Resolving Crawl Errors:
- Check server logs: Identify issues causing server errors and fix them.
- Monitor server health: Regularly check logs to catch recurring errors promptly.
- Fix soft 404s: Ensure pages displaying “page not found” messages return the correct 404 code and provide helpful information to users.
By addressing crawl errors, you ensure your website is properly crawled and indexed, leading to better search ranking and organic traffic.
4D. Identify Low-Quality Pages (And The Recommended Tools)
Optimizing your website for crawl efficiency isn’t just about technical SEO but also about content quality. Google’s Quality Guidelines are a good place to start understanding how Google values content and what makes good and bad content, which can help you better save your limited crawl budget from being drained.
Here are some examples of low-quality pages that hurt your crawl budget spending:
I. Duplicate content
Duplicate content is a major enemy of SEO, leading to both lower rankings and wasted crawl budget. It confuses Googlebot about which version of the content to index, potentially hurting the ranking of all involved pages.
Here’s how to tackle duplicate content and optimize crawl efficiency:
- Identify duplicates: Use tools like Seobility to find duplicate content lurking across your website.
- Consolidate or remove: For identified duplicates, consider consolidating them into a single, stronger page. If the content isn’t valuable, removal might be the best option.
- Focus on unique value: Aim for every page to serve a clear purpose and offer unique value to users. Avoid auto-generated pages or those lacking a distinct service or information.
By eliminating duplicate content and prioritizing unique, valuable pages, you ensure Googlebot spends its crawl budget efficiently, focusing on the content that has the most potential to rank well in search results.
II. Pages that receive high bounce rates
Metrics like bounce rates and average time on page can hint at user dissatisfaction with certain pages. You can use Google Analytics to provide valuable insights into pages that users find less valuable.
High bounce rates and low average time on page typically point towards content that doesn’t meet user expectations. However, remember to consider all factors, as a high bounce rate may just mean that users found their answers quickly.
III. Other low-value pages
SEO auditing tools, like SEMrush and Ahrefs, can be incredibly helpful in identifying low-value pages. These tools provide comprehensive site audits, highlighting issues like poor keyword rankings, broken links, and weak backlink profiles. Regular audits help you keep track of your pages’ performance, allowing you to promptly address any issues that arise.
4E. Use JavaScript Pre-rendering Solution
JavaScript’s loading can delay the rendering of content on your pages.
Googlebot, on a tight crawl budget, might not wait for these elements to load, leading to missed content and a less accurate representation of your page in Google’s index. The question is, how can we mitigate this issue? The answer lies in two primary solutions: dynamic rendering and prerendering.
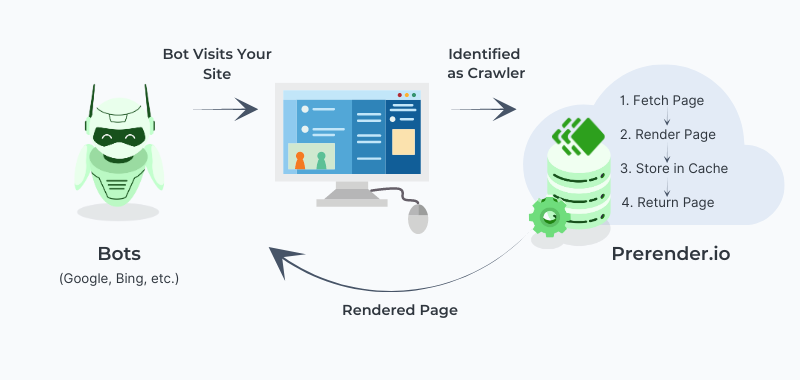
Dynamic rendering involves serving a static HTML version of your page to bots while delivering the usual JavaScript-heavy page to users. However, as stated in the official Google documentation, dynamic rendering is a workaround, given the complexity of implementation. Conversely, open-source tools like Prerender make the process effortless.
Related: How to Install Prerender
The prerendering process detects whether a user or a bot is requesting a page, ensuring that the 100% cached version is served to bots and the dynamic one to users. Prerendering also impacts perceived page speed as Googlebot receives a fully rendered HTML snapshot, indirectly boosting your SEO.
Services like Single Page Applications (SPAs) present a unique scenario. These applications heavily rely on JavaScript, making them particularly susceptible to crawl issues. However, prerendering ensures that all content of a SPA is discoverable by Googlebot. And, as prerendering can be implemented on your CDN—e.g. by using Cloudflare Workers—getting it implemented requires no code changes or support for specific frameworks like React or Vue.
Prioritize Google Crawling to Your Important Pages
The process of guiding Googlebot to effectively crawl important URLs is no easy task, but it’s one well worth undertaking. By identifying and blocking low-value pages, optimizing your sitemap.xml, and embracing prerendering services, you can enhance your crawl efficiency and boost SEO performance.
Try Prerender today to improve your site’s indexation, drive more traffic, and boost your revenue.