JavaScript has seen wide adoption in the ecommerce industry, with “up to 80% of popular US-based ecommerce stores using JS on crucial content such as product descriptions,” according to Onely.
And it’s easy to understand why.
JavaScript allows store owners and developers to create immersive experiences, providing customers with a more user-friendly buying experience. This, in turn, translates into higher conversion rates, engagement, and customer loyalty. But JS can also become a problem when implemented incorrectly as we look to uncover the common mistakes on JavaScript e-commerce sites.
In fact, in the same study, Onely found that from all pages analyzed, at least 25% up to 90% of JS content wasn’t indexed. So, in today’s article, we’ll explore the five most common mistakes developers and store owners make when implementing JavaScript and how to fix them, improving indexability and ranking.
5 Common Mistakes on JavaScript Ecommerce Sites
1. Blocking Crawlers from Accessing Robots.txt File
The robots.txt file is a file in your server that tells crawlers and bots how to handle your URLs by providing certain directives. For example, you can use this file to prevent Googlebot from crawling administrative pages or blocking content from behind login walls, but you can also use it to specify the pages that shouldn’t be indexed. (This file is important because it gives you more control over how your crawl budget is used and what content gets displayed on search results.)
Preventing Google from crawling a directory filled with pages you don’t want to get indexed ensures that your crawl budget is used on URLs you do want in search results. However, by mistake or because of misinformation, some developers or store owners block every resource that’s not an HTML file – after all, why do you want to waste crawl budget on files that will not be shown in search results, right?
Although it sounds logical, it’s actually a wrong practice!
The indexing process can be broken into three main steps:
-
- Crawling – discovering your URLs
- Rendering – generating a visual representation of your page
- Indexing – categorizing your page to being added to the search engine’s directory
All pages go through this process – even static HTML pages need to be rendered – but JavaScript sites require a more advanced rendering process because JS needs to be compiled, executed, and finally rendered.
The rendering process it’s important for Google because that’s how they can measure different metrics like core web vitals and responsiveness, but in a JS case, it’s also essential to access the whole content and functionality of your page. Can you see the problem with blocking JS files now?
If Google can’t access your JavaScript resources, it won’t be able to see any content that’s injected through AJAX, resulting in missing content, links, thin content issues, and, most likely, unindexed URLs.
The good news is that solving this issue is actually quite simple, but we recommend asking an SEO professional for guidance or providing our robots.txt optimization guide to your developers before committing to any major changes.
Within the robots.txt file, you’ll find some directives like the following directive:
| Disallow: /js/Disallow: *.js$ |
All you have to do is delete these lines. On Google’s next crawl, it’ll start picking up on your JS resources.
Still, if you want to be sure, you can also add an allow directive for a couple of months while the rendering issues start to resolve.
| Allow: /js/Allow: *.js$ |
It might take a while, but as Google crawls your pages, the issue should be resolved. Learn more about AJAX and SEO.
2. Relying on Google to Render Your Dynamic Pages
Ecommerce websites usually use JavaScript to build dynamic functionalities like adding a related items carousel, product lists to category pages, product filtering, and even injecting crucial content like product descriptions. Although these provide a better experience for customers, search engines are not equipped to handle JS efficiently due to limited resources like time and processing power.
As your store grows, you’ll have hundreds of thousands of URLs that need to be crawled, rendered, and indexed, shrinking your crawl budget. As it is, dynamic content burns through your crawl budget fairly quickly, causing issues like partially rendered content, meaning search engines will judge your pages based on unfinished content, hurting your rankings, crawlability, and indexability.
This is the reason client-side rendering (CSR) is discouraged for websites that want to get organic traffic from search engines.
If you’re using frameworks like React and Angular, CSR is the default rendering option, but both of these frameworks can be configured to use server-side rendering (SSR), which is a better option if you want your pages to be found on search results.
SSR vs. Dynamic Rendering
SSR works by making your server handle the rendering of your page and then sending it to search crawlers when the page is requested. This way, search engines don’t have to render your JS code and can find/index the content completely.
Still, SSR doesn’t come without problems. To implement server-side rendering, you’ll need to invest in server equipment capable of handling both the traffic from crawlers and users, as well as the rendering process at scale. You’ll also have to consider engineering hours for implementation and maintenance and possibly rewriting your code base to use, for example, Angular universal – the entire process can take months.
After all this hard work, SSR still has some limitations:
-
- Slow server response time – because every page will be rendered on your server upon a crawler request, the time from request to server response is longer. This can negatively affect your crawl budget and SEO scores.
- Low time to interactive – your server will take care of rendering the visual representation of your page, but search engines still need to take care of the JavaScript necessary to make the page interactive.
- Third-party JS isn’t rendered – due to limitations, your server won’t render any 3rd-party JS, so Google will need to take care of those bits, which can be crucial if your page is using these scripts for certain functionalities.
A better solution with none of these drawbacks is using Prerender to generate a fully functioning, rendered version of your pages (including 3rd-party scripts) and deliver them to search engines – this process is known as dynamic rendering.
Unlike SSR, Prerender caches the rendered version of your pages, increasing your server response time to an average of 0.03 seconds. Furthermore, the cached version is completely interactive and stable, improving your core web vital metrics to near-perfect.
The best part is Prerender just requires a simple installation with your tech stack to start caching your pages. No need for massive upfront investment in servers or complicated software implementations.
If you want to learn more, here’s a complete walkthrough of how Prerender works.
3. Using JS Pagination and Event-Driven Internal Links
You’ve probably heard that internal links are crucial for your website’s success, but do you know why?
The role of internal links and paginations becomes clear once you understand how crawling works.
In simple terms, Google crawls your site by following each and every link it can find under your domain. When it downloads your HTML file, it’ll push every link it finds in it to the crawl queue. Then, it’ll follow those links and repeat the process.
However, for this process to work, two things must happen: the link has to be findable, and the crawler has to have access to the link. Let’s explore two scenarios when one of these conditions aren’t met:
Infinite Pagination and SEO
Ecommerce sites tend to have tens of categories, each one potentially with hundreds of products, which would make these category pages too long for users, hurting the shopping experience.
One way to handle these big numbers of products is by implementing infinite scroll pagination.
When customers navigate to a category page, they are presented with, let’s say, ten products – this number is much more manageable for the eye. But once they scroll to the bottom of the page, ten more products are injected into the list using JavaScript without having to refresh the page, allowing the shopper to look through the full catalog of products in small bits uninterruptedly.
Even though it sounds great for ecommerce sites to use this pagination style, the problem is that search engines can’t scroll down to trigger the event, so they will only get to see the first ten products. In other words, all other products within the category won’t be discovered by crawlers and won’t get indexed by search engines.
If you care about customers finding your products through search engines, we recommend using a traditional numbered pagination. In this style, your catalog is broken down into different URLs like:
-
- domain.com/snowboards/page-1
- domain.com/snowboards/page-2
- domain.com/snowboards/page-3
Every URL displays different content (products) and is easily crawled and indexed by search engines.
Nevertheless, if you still want to implement infinite scrolling, Potent showed an interesting strategy to use infinite scrolling while generating pagination in parallel that crawlers can follow.
Resource: Discover the 4 most common SEO pagination problems and how to fix them
Event-Driven Internal Links
Another common scenario is using JavaScript for internal links, which would make it impossible for Google to follow them – this includes how you structure your links on paginations too.
During the crawling process, Google will look for links by identifying all <a> tags within the page, and following the URL inside the href attribute.
| <a href=”https://prerender.io/blog/why-javascript-complicates-indexation-and-how-to-fix-it/”> |
This is the structure Google and all other search engines will be expecting, so most other implementations won’t work.
Crawlers are bots with very specific directives to follow and can’t interact with your page as regular users would. That means none of the following techniques will work:
| <a onclick=”goTo(‘page’)”>Anchor</a><a href=”javascript:goTo(‘page’)”>Anchor</a><span onclick=”goTo(‘page’)”>Anchor</span> |
To avoid crawling issues, use the traditional link pair of <a> + href.
When possible, also add all your links directly to the HTML document. If your links are injected through AJAX calls, even if implemented correctly, Google can miss them during the rendering process.
If you must add your links through JavaScript, then prerendering your pages would be the best solution to ensure fast crawling times.
4. Ignoring JS Optimization for Mobile Devices
As mobile traffic increases, more and more customers are making their purchases through their phones, making mobile optimization more important than ever. In spite of that, most developers focus on things like making the page responsive or optimizing images. While those are essential optimizations every website needs, mobile and desktop devices have many differences to account for.
Most mobile devices are meant to be carried on the go, so they count with slower network connections than desktops connected to high-speed WiFi. Also, mobile devices lack processing power, which makes it harder for them to execute JavaScript.
Such is the gap that mobile devices load seven times slower than their desktop counterparts:
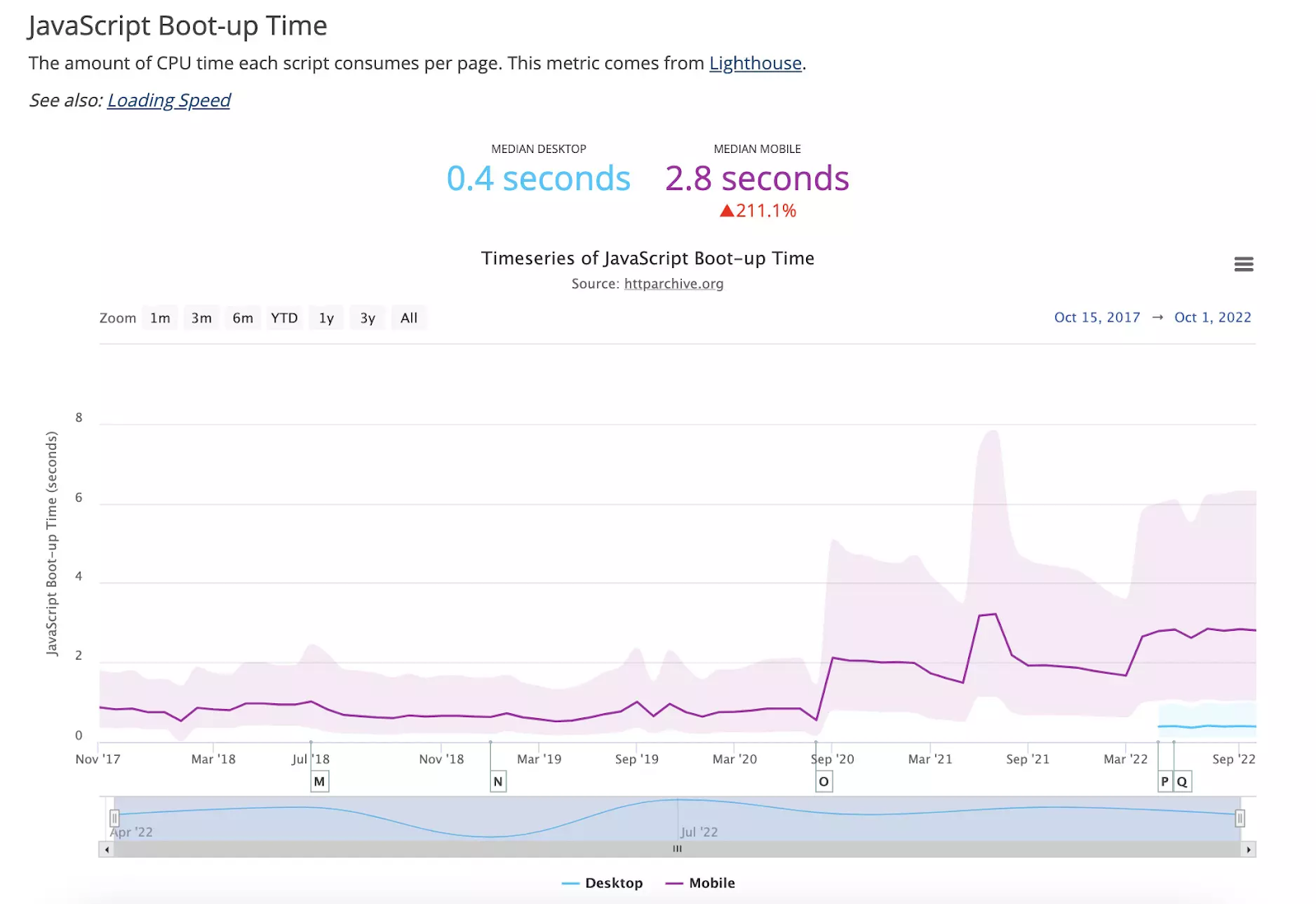
Source: HTTP Archive
Explaining why even the biggest ecommerce sites have a huge difference between mobile and desktop page speed scores:
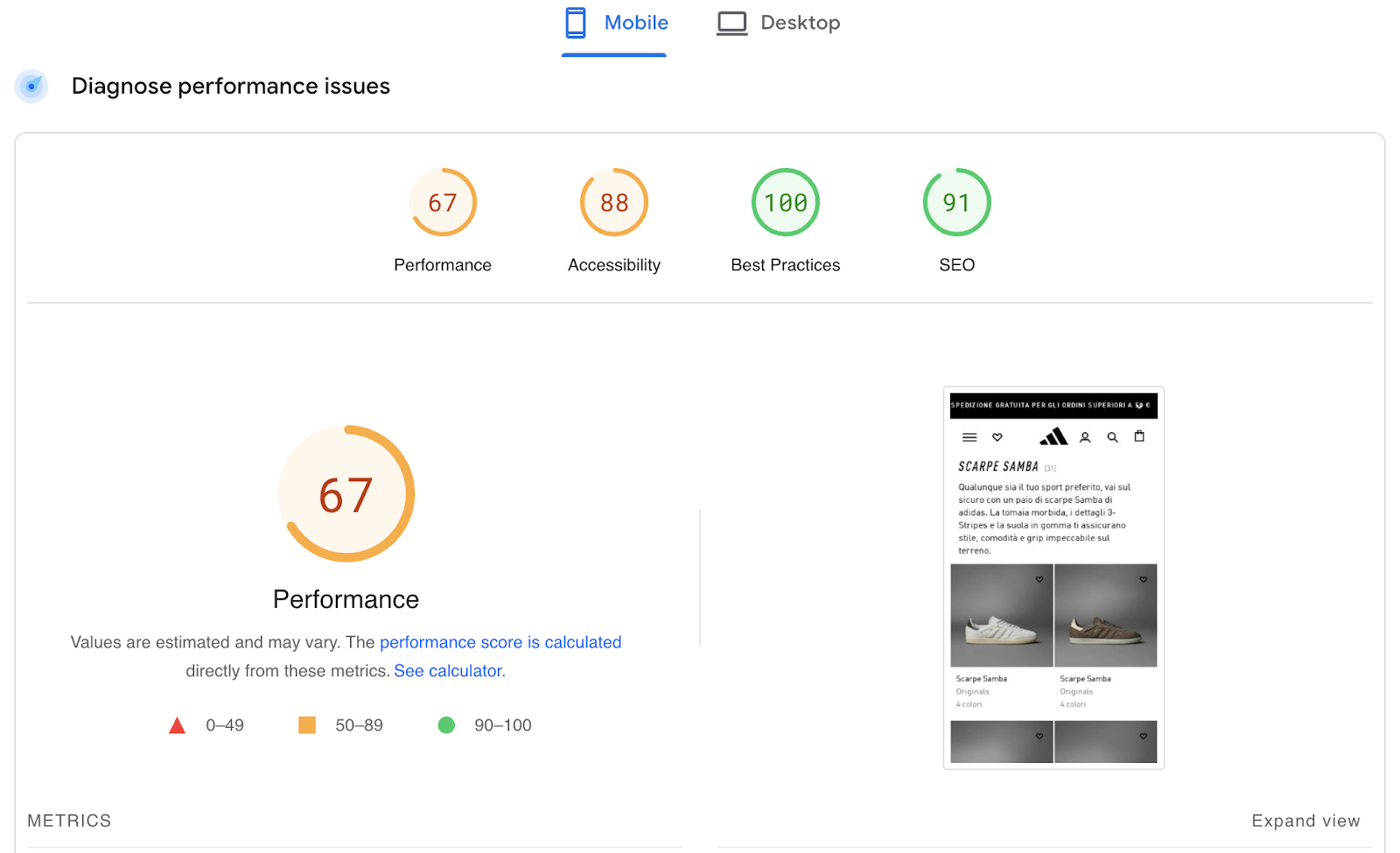 |
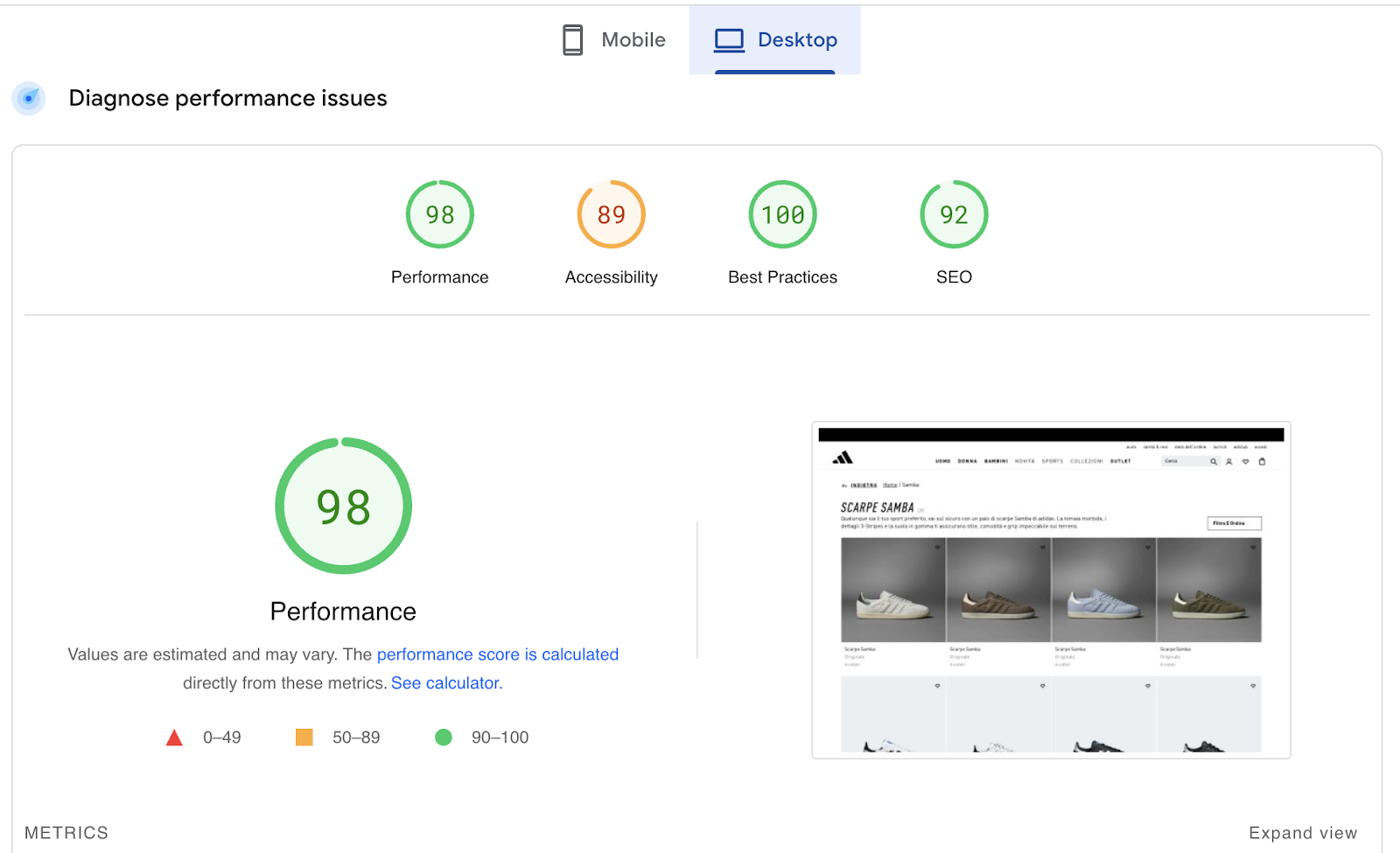 |
URL: https://www.adidas.it/samba
Optimizing your JavaScript for mobile devices can make a huge difference in your rankings, especially now that Google has adopted a mobile-first indexing approach, so the mobile experience will now affect your desktop’s site version rankings.
To handle JS more effectively for mobile devices, you can follow our 7 best practices for mobile JavaScript optimization. It will walk you through the best solutions to keep your mobile performance at the top of its game.
Quick spoiler, you should start learning about the Async and Defer attributes and code splitting.
5. Using Hashed URLs
From all of the issues in the list, this is maybe the most common problem and one that can break your entire SEO performance if not corrected quickly.
As we mentioned before, JavaScript frameworks use client-side rendering by default to ensure fast load times after the website or web app has initialized. One way they do this is by injecting new content based on the customer’s interaction with the page and only updating those elements.
Since the page doesn’t have to be refreshed completely, the website is more snappy and provides a seamless experience to the user.
To accomplish this, JS frameworks use Hashed URLs like this:
| https://domain.com/categories/#/snowboardshttps://domain.com/categories/#/snow-shoes |
The browser will interpret this as an anchor link or a fragment, which points to a section within the same document. This prevents the browser from refreshing the page, and instead, it renders only the specified content.
In terms of SEO, this is exactly the problem. Search engines will interpret this structure the same way as browsers, so they’ll think everything after the pound (#) sign is part of the same URL, instead of a different, separate page.
Google will think of all of the following URLs as being, for example, the homepage:
| https://domain.comhttps://domain.com/#/bloghttps://domain.com/#/gift-guideshttps://domain.com/#/about-ushttps://domain.com/#/return-policyhttps://domain.com/#contact-us |
And will only index the page before the hash symbol. Replicate this issue across the entire website, and you’ll get the majority of your content ignored by search engines.
One solution that gets tossed around is using a hash-bang (#!). Instead, which Google has recommended as a solution to tell its crawlers to consider the entire URL as a unique page and not a fragment.
It’s important to know that this is just a workaround while you fix the root of the issue and not a permanent solution.
To ensure you’re using SEO-friendly URLs, use the history API to generate a traditional structure for your URLs like:
| https://domain.comhttps://domain.com/bloghttps://domain.com/gift-guideshttps://domain.com/about-ushttps://domain.com/return-policyhttps://domain.com/contact-us |
These are cleaner, unambiguous URLs that will allow your content to live in an easy-to-crawl and index URL. You can learn more about generating clean URLs in this guide.
Conclusion
At this point, you are well aware of the common mistakes on JavaScript e-commerce sites. These mistakes are not limited only to the five discussed in this article. Leverage SEO tools like Google Search Console to monitor your website’s health and identify potential crawl or indexing issues related to JavaScript.