If you’ve ever been crawled but currently not indexed, you’ve likely encountered this coverage report before:
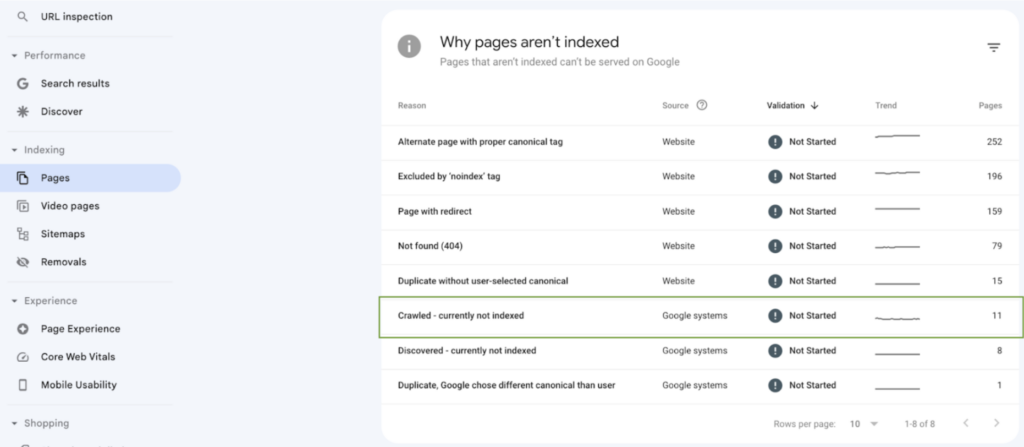
This report lists all the URLs that Googlebot has crawled, but they weren’t selected to be indexed.
Note: The “Crawled – currently not indexed” report is different from the “Discovered – currently not indexed” report. The latter is a report that lists the URLs discovered during the crawling process, but they were scheduled for crawling at a later date due to crawl budget issues. Sadly, the report doesn’t explain why the page wasn’t indexed, so fixing these URLs won’t be as straightforward as expected. Instead, you’ll need to think about this as a site-wide issue, as Mueller explained:

With that being said, let’s explore why URLs end up in the “crawled but not indexed” report and what you can do to get your pages in search results!
🔍 Want to boost your SEO? Download the free technical SEO guide to crawl budget optimization and learn how to improve your site’s visibility on search engines.
When You Shouldn’t Worry About “Crawled – Currently not Indexed” Status
As with everything else in SEO, every decision you make is based on context. Not because you have URLs appearing inside the “crawled – currently not indexed” report means there’s a problem with your site. There are occasions when there’s no problem, and you shouldn’t pay much attention to it.
Google has become very good at making decisions on its own when there are no clear directives on handling specific pages. For example, on the same page, we used as the example above, we can find these URLs listed in the report:

Although they should look deeper into it, there’s no good reason for having these URLs indexed. Because Google can understand these scenarios, they made the decision to exclude these pages from the index.
In some other cases, it is just a mistake. That means there’s a good chance your pages were indexed, but the report isn’t reflecting it yet. To look for false positives, you can do a Google search using the site search operator and look for the URL supposedly excluded.
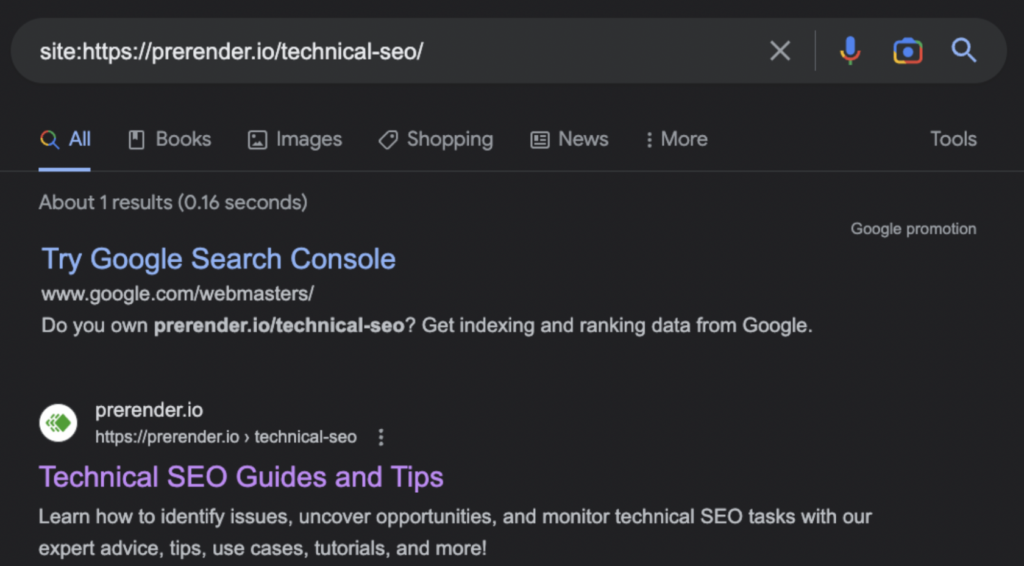
If you can find the URL in search results, then there’s nothing else to do but be happy for a successful indexation! To summarize, before you jump into fixing mode, first make sure the page was actually excluded and that you want that page to appear in search results.
Technical SEO and the “Crawled – Currently not Indexed” Coverage Report
Before jumping into content-related causes, let’s first discuss the technical reasons your pages could be getting excluded from Google’s indexed search results, as technical SEO is the foundation for your content to be properly crawled and indexed.
Site Architecture and Indexation
The information architecture of your website is, in simple terms, the hierarchical order of the pages and how they are related to each other through internal links.
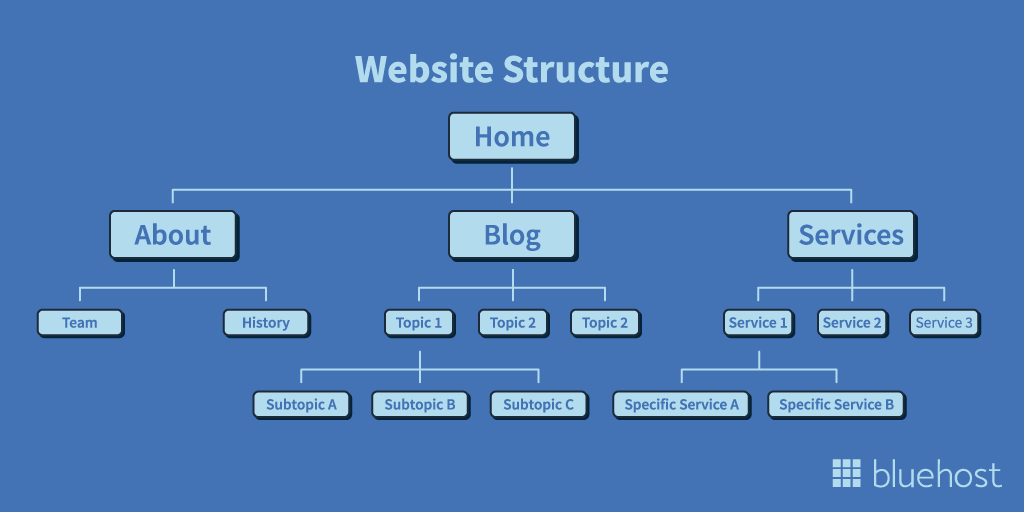
This is important for customers and bots alike. For the first group, a good site structure makes it easier to navigate the site, find information and understand how to use your website. On the other hand, bots crawl your site by following internal links, so your site structure accomplishes three things:
- Allowing Google crawler to find all your pages
- Signaling Google the hierarchical importance of your pages
- Helping Google understand the relationship between pages
Discovery and categorization are critical processes for proper indexation, so these three factors have a direct impact on your site’s indexability.
Now, in what cases can your site architecture result in not indexed but crawled pages?
- The crawler finds orphan pages – an orphan page can be interpreted as irrelevant. After all, if there are no other pages connecting it to the rest of the structure, how important could it be? This can result in your URL not getting indexed even if Googlebot can find it in the sitemap.
- Googlebot can get lost – the crawler depends on your site structure to navigate your site, so without a logical organization, Google can’t understand where it should be going and what’s the relationship between pages.
A good site architecture will organize information in a logical way. For example, all pages talking about similar topics should link to each other (topic clusters), all category pages and pillar pages should have a place within the main navigation menu, and every page should be findable from multiple parts of the web (interlinking).
You can use this guide to find orphan pages and improve your site structure.
Page Performance and Core Web Vitals
Page speed is critical to user experience, and as such, Google has broken page speed down into three distinctive core web vitals (CWVs) to measure your site performance more closely.
The goal of this measurement is to ensure that only websites with great user experience are indexed in Google and as a tie-breaker for search results rankings. In other words, meeting Google’s performance expectations is required for your URL’s eligibility for indexation, and it directly influences your rankings.
If you are failing on CWVs, Google will ignore your pages until these values meet their standards.
There are many strategies you can use to speed up your site, but it’s a case-by-case task, so it’s almost impossible to give you accurate optimization steps without knowing more details about your site.
Still, you can use our guides to evaluate your site and determine what the best strategies are:
- What Are Core Web Vitals & How to Improve Them
- Page Speed Tips and Stats to Know
- 7 Tips For Creating Mobile-Friendly JS Sites
Important: Don’t sleep on mobile speed optimization. Google has now moved completely to mobile-first indexing, making mobile performance a top priority if you want to improve indexation and rankings.
| Improve Core Web Vitals to Near-Perfect with Prerender. Optimizing core web vitals for a static HTML website is one thing, but optimizing them for a JavaScript-based website is another story. It requires a lot of knowledge, work, and resources to ensure your JS files are optimized and not blocking the rendering process for bots. Still, after all optimizations, search engine bots are barely able to handle your dynamic content, negatively impacting your CWVs which, in our experience, usually plateau at a 50 – 60/100 score. However, after installing Prerender on your site, you’ll quickly achieve 90+/100 scores Page Speed Insights scores (including near-perfect core web vitals) site-wide and a server response time of 0.03s on average. |
Google Not Being Able to Access Your Dynamic Content
As mentioned in the note above, search engines and JavaScript aren’t best friends. So much so that most search engines can’t handle JS at all, and those that can (Google and Bing) recommend using dynamic rendering to take the burden off the crawler’s shoulders and avoid indexing issues.
One of these issues is getting your pages excluded from the search engines index due to thin or missing content.
When a person enters your site, their browser has no problem downloading, executing, and rendering your page, but when a crawler enters, it starts a resource-intensive process that can take 9x longer than normal.
Most often than not, the process gets cut because of a depleted crawl budget or timeouts, causing crawlers to obtain a partially rendered or blank page.
As you can imagine, these kinds of pages reflect poorly on your site and provide little to no reason for Google to index them – if they don’t provide value, why waste storage and resources on them?
Although you can implement hard-coded strategies like server-side rendering (SSR) or static rendering, these require substantial upfront investment (around $100k to get started), months of engineering work, and won’t work at the scale or effectiveness you’d want to get an edge on your competitors.
That’s exactly where a tool like Prerender can make a difference and bring you closer to your goals.
Prerender requires a simple middleware installation, which takes a couple of hours, and submitting an updated sitemap for faster results. After it’s installed, Prerender will crawl your URLs and start generating and caching a fully rendered and functional version of all your pages to be delivered to search engines on demand.
When Googlebot or any other crawler requests your pages, Prerender will deliver the cached version with all your content, links, and features completely ready for indexation.
No upfront investment on expensive server equipment or long development cycles. Just an easy plug-and-play tool to get your content 100% indexed across the board.
| Extra Note: Although this is less common, we’ve noticed redirected pages are sometimes added to this list. If you’re noticing all the target pages of redirections are getting into the “crawled – currently not indexed”, there’s a chance it isn’t picking up the signals that it should be dropping the old URL and indexing the new URLs (target page). As Moz pointed out in their article, one solution is to create a temporary sitemap to make Google crawl the target URLs more often, speeding up the replacement process of the URLs within the index. Another potential issue to pay attention to is redirect chains. These chains force Googlebot to spend resources following long sequences of redirects, or can outright trap crawlers in an infinite loop.If these problems are common on your site, this clearly indicates poor UX, and Google will ignore your pages. Here’s a clear step-by-step process to fix it. |
Are Content Quality Issues Holding You Back?
Content is the cornerstone of your site. People search for information on Google. They want to learn something, improve their skills and clear some questions, and Google continuously analyzes the web to find the best answer to all queries.
Because search engines’ business is knowledge and information, only recommending high-quality, useful content is the main objective of their algorithm, and producing the best pieces of content possible should be yours.
For your pages to be indexed, your content quality should be on point and respect Google guidelines to avoid being penalized.
So what’s the first thing to keep in mind?
1. Create Original, Useful Content
You’ve probably heard this over a million times, but it isn’t very clear what good content is, right? Well, although there is no one unique definition, certain traits make content good.
First of all, it should have a degree of originality. Notice we didn’t say it has to be completely original. After all, you found this page within a list of search results showing somewhat similar content.
However, originality comes from two main sources:
- It is not plagiarized content – even if you copy content from another language and translate it to another, it still infringes copyright policies and will get your pages banned from the index.
- It has a distinctive angle – and this is the key to your content success.
Think about it. Why would Google promote your content if it tells the same story and information other hundreds of articles are already telling?
Having a unique angle, or original point of view, or presenting new information can make the whole difference. That’s why original data-driven content works so well.
You have to ask yourself, is my page adding value to the conversation, or am I just rehashing what it’s already out there?
The second part of the equation is your content’s usefulness, and that comes down to whether or not it aligns with the search intent behind the query.
For example, if you want to rank for the keyword “how to write a book”, creating a landing page for a book on the topic isn’t the right move, even though it could potentially answer the question.
No, people looking for this query do not have a purchase intent. They want information. So an article or step-by-step guide explaining the process of writing a book will have a higher chance of ranking, as it’ll be useful for the person searching for the term.
Note: Of course, you can then promote your book within the article.
If your pages are both original and useful, your website will have fewer indexation issues and a higher probability of ranking organically.
Remove Duplicate Pages
There are many reasons for Google to consider pages as duplicates. One common reason is when pages have similar content or are trying to rank for the same queries.
Because there’s little value in indexing two pages from the same domain showing almost the same information, Google will declare one as duplicate and the other as canonical, excluding the first and indexing the second.
Before you say it, yes, there are a couple of reports that could better fit this situation, like:

However, because we don’t really know the criteria Google uses for the “crawled – currently not indexed” status, there are times when pages considered duplicate can end up here.
To fix these pages, you can do two things:
- Consolidate pages – if you’re noticing too many similarities or Google is considering two pages as the same, there could be a chance that the topic should be discussed in only one URL. You can take the URL with the best link profile or the oldest and merge all content from all duplicates into one longer content.
- Add extra content to differentiate your pages better – there’s also the chance you didn’t add enough context for the pages to be different. This is very common when two pages are talking about the same topic at their core but from two different angles or with landing pages or category pages showing similar information.
Of course, unintentional duplicate content issues can influence your indexability, which is a little harder to identify and fix.
Especially if you are running an enterprise-level website, these issues can be happening because of code errors, dynamic URLs getting created, and more.
To get deeper into this, follow our duplicate content guide to find and fix all affected URLs and avoid unnecessary penalizations.
Wrapping Up
Dealing with the “crawled currently not indexed” coverage status is about improving your site’s quality to avoid it altogether. This report doesn’t give a clear reason, most likely, because it acts as a wildcard report.
When you see URLs getting into the report, you should take it as an early sign of potential indexing issues on your site.
After verifying that your URLs are indeed getting excluded from the index, you need to audit your website and build an optimization plan to provide Google with the necessary signals and information to get your pages in search results.
Indexation is the first step towards SEO success, so getting your pages into search results has to be a priority at every stage of your business.
To help you in this process, we’ve created a series of guides that’ll walk you through the best practices and strategies you can implement today:
- 6-Step Recovery Process After Getting De-Indexed
- 10 Ways to Get Your Website Indexed Faster
- 10-Step Checklist to Help Google Index Your Site
- 5 Ways to Maximize Crawling and Get Indexed
- Why JavaScript Complicates Indexation
Thanks so much for reading until this point. Now is the time to get to work and start implementing everything you’ve learned today.
We hope to see your pages back in the SERPs soon!